


Centralized data projects felt bold a decade ago. You built a lake, hired a central data team, and pointed everyone at a single source of truth. It worked. At least it used to until the organization tripled in size, compliance rules multiplied, and every business unit started demanding its own real-time dashboards.
Suddenly, that single source became a choke point. Queues formed, context leaked away, and decision cycles slowed to a crawl. Engineering leaders found themselves defending yesterday’s architecture while tomorrow’s product launches slipped.
A data mesh paradigm addresses that pain by pushing ownership back to the people who know the data best. Instead of forcing everything through one pipeline, it distributes data creation, quality, and access across domain teams.
The result is fewer data silos, faster iteration, and an architecture that scales with the business rather than against it. For enterprises juggling privacy regulations, multi-cloud footprints, and relentless feature delivery, the shift is not hype. It is a practical response to real limits in traditional data management models.
Defining Data Mesh Without the Jargon
Think of data mesh as an operating model for data, not a single product you can buy. At its core, it is a decentralized data architecture in which each business function—marketing, finance, logistics—creates and maintains multiple data products. Those products live in a shared fabric of standards that makes them easy to discover, secure, and combine.
Unlike a monolithic data lake, a mesh does not pull every record into one bucket before value appears. Data stays close to data sources, enriched by the people who generate and consume it. That proximity reduces hand-offs and preserves context, two things senior leaders crave when they face tight delivery timelines.
Yes, you still need data ingestion pipelines, catalogs, and lineage tooling. The difference lies in distributed data architecture principles that treat infrastructure as an enabler rather than a bottleneck.
The Four Principles of Data Mesh
These four principles are the foundation of data mesh. Each one addresses a different pain point in centralized data architectures and works together to create a scalable, accountable, and business-aligned data environment.
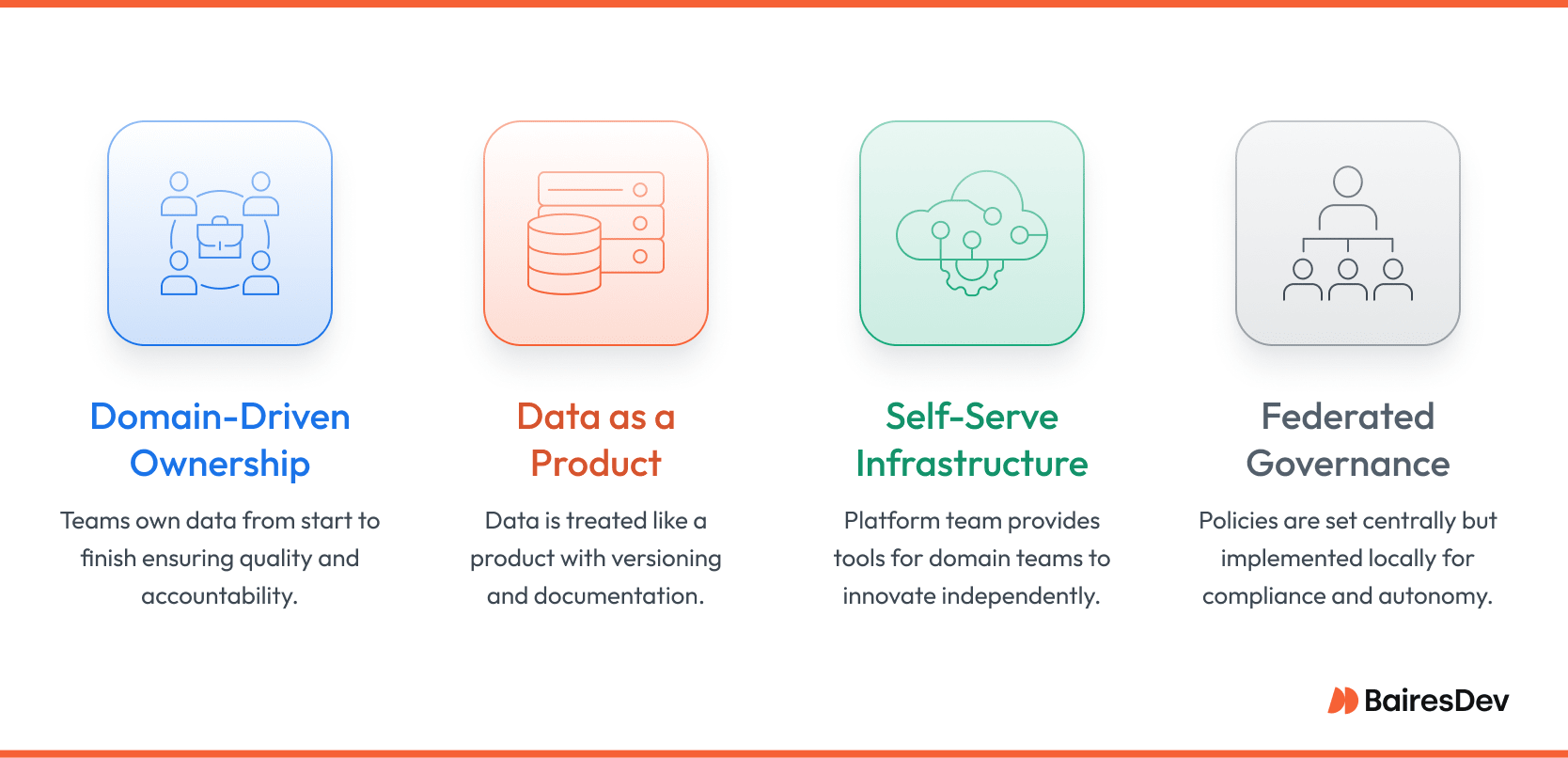
Domain-Driven Ownership
Every domain team owns its data from ingestion through retirement. That ownership includes schema design, pipeline reliability, and ongoing quality controls. By turning domains into first-class data providers, enterprises replace ticket queues with accountable data domain teams and unlock faster time-to-insight.
Data as a Product
In a mesh, data is versioned, documented, and supported just like any other product. Teams define contracts, apply test coverage, and publish release notes. Treating information this way eliminates the shadow spreadsheets and stale reports that erode trust, and it encourages teams to create data products deliberately rather than by accident.
Self-Serve Data Infrastructure
A dedicated platform team supplies the automation, storage, and observability that let domain engineers focus on business logic. The platform abstracts low-level plumbing into intuitive workflows. When self-service works, developers innovate without waiting for central approval, yet security and lineage remain intact.
Federated Data Governance Policies
Standards matter, but gatekeepers slow delivery. Federated data governance threads that needle.
A cross-domain council sets policies for privacy, lineage, and access controls while domain teams implement them locally. The model scales compliance without forfeiting autonomy, which is vital when regulations evolve faster than release cycles.
Together, these principles replace brittle, centralized pipelines with a living, domain-aligned ecosystem. Executed well, a data mesh turns data into a leveraged asset: accessible, well-governed, and always ready for the next product milestone.
From Central Lakes to Distributed Mesh: Why This Shift Matters
Early enterprise data strategies revolved around one idea. Put everything in a data lake, keep storage costs low, and ask a centralized data engineering team to curate insight for the whole company. The approach succeeded when business questions arrived at a leisurely pace, yet reality moved faster.
Data scientists demanded raw telemetry yesterday, finance asked for reconciled numbers by noon, and security flagged access risk in every request. The central data team became a bottleneck because every pipeline, schema change, and access ticket flowed through the same limited group.
A lake also stripped records of vital context. The moment events left source systems, they arrived as raw data without a domain language. Analysts scrolled through thousands of tables and guessed which column contained the value they needed. Data ownership blurred. Time-to-insight stretched from days to weeks.
A data mesh architecture tackles these limits through distribution. Instead of one lake, each domain publishes authoritative, well-documented data products. They own schemas, maintain lineage, and expose contracts that downstream teams can trust. Responsibility shifts from a gatekeeper model to a federated model in which data producers and data consumers negotiate quality upstream.
That realignment eliminates the backlog cycle and restores context because data stays close to its business process. For companies facing regulatory pressure or aggressive product roadmaps, the move from centralized to distributed is more than an upgrade. It is a survival strategy.
What Enterprise Teams Actually Need to Implement Data Mesh
Moving theory into practice takes three complementary groups. The first is the domain team. Data engineers and analysts inside a department ingest events, transform them, and publish certified datasets. They manage their own data pipelines, uphold quality metrics, and answer for any break in lineage.
Second comes the data platform team. This group builds the self-serve data platform that every domain relies on. They provide ingestion frameworks, containerized transformation runners, a unified data catalog for discovery, and automated permission workflows. When domain engineers spin up a new pipeline, they do not file a ticket; they click a template, choose a retention policy, and ship.
Third stands the governance committee. Senior architects, security leaders, and compliance officers formulate policies that span the enterprise. They define encryption requirements, retention schedules, and naming conventions, then rely on platform enforcement so that rules never depend on human vigilance alone.
Tools matter, but clarity of responsibility matters more. Ownership lives in the domain, observability lives in the platform, and guardrails live in governance. That triangle is what turns the slogan “treat data as a product” into an operational fact.
How to Make the Transition Work
Successful organizations treat mesh adoption as a program, not a sprint.
Data leaders start by choosing one or two mature domains with stable source systems and motivated engineers. These pilots create tangible value and prove that new ownership patterns reduce cycle time without sacrificing security. Early wins fund political capital for broader rollout.
While pilots evolve, the platform team hardens foundational data infrastructure. They automate lineage capture, integrate role-based access controls with single sign-on, and expose usage metrics so leadership can measure adoption. Parallel to engineering tasks, the governance committee drafts a living policy document. It spells out naming standards, incident escalation paths, and service level objectives for every published dataset.
Education closes the loop. Workshops teach domain data engineers how to write product-grade transformation code. Lunch-and-learn sessions walk analysts through the catalog and show where to file enhancement requests. Internal communications celebrate success stories so that remaining teams see mesh as empowerment rather than overhead.
Enterprises that implement data mesh with this phased, people-first strategy experience a measurable shift. Time to provision new data platforms drops from weeks to days. Compliance audits complete faster because lineage is captured automatically. Most importantly, product teams no longer wait in line for insight. They own it.
Common Missteps and What to Watch For
Projects that fail to deliver mesh benefits usually stumble in familiar ways.
Overengineering
The first misstep is overengineering the platform before a single domain publishes data. Teams spend months debating columnar formats and network topologies while the business waits for results. Momentum dies, and leaders question the entire initiative.
Policy Enforcement
A second trap is treating policies as optional. Without clear access rules and quality metrics, domains drift toward incompatible schemas and half-documented tables. What looks decentralized soon feels chaotic.
Another recurring error emerges when ownership stops at the data layer. Domain engineers produce tables, yet no one sets service levels or monitors user adoption. The product mindset evaporates. Data consumers lose trust, and they quietly rebuild spreadsheets.
Culture
Finally, organizations underestimate the cultural shift required. Centralized BI teams may feel their influence slipping and resist change. Executive sponsors must communicate that mesh expands opportunity for everyone by freeing experts to focus on higher-value tasks instead of ticket triage.
Observation, policy automation, and transparent success metrics keep these pitfalls contained. When teams see real-time usage dashboards and understand how quality scores affect their reputation, accountability follows naturally and the mesh matures.
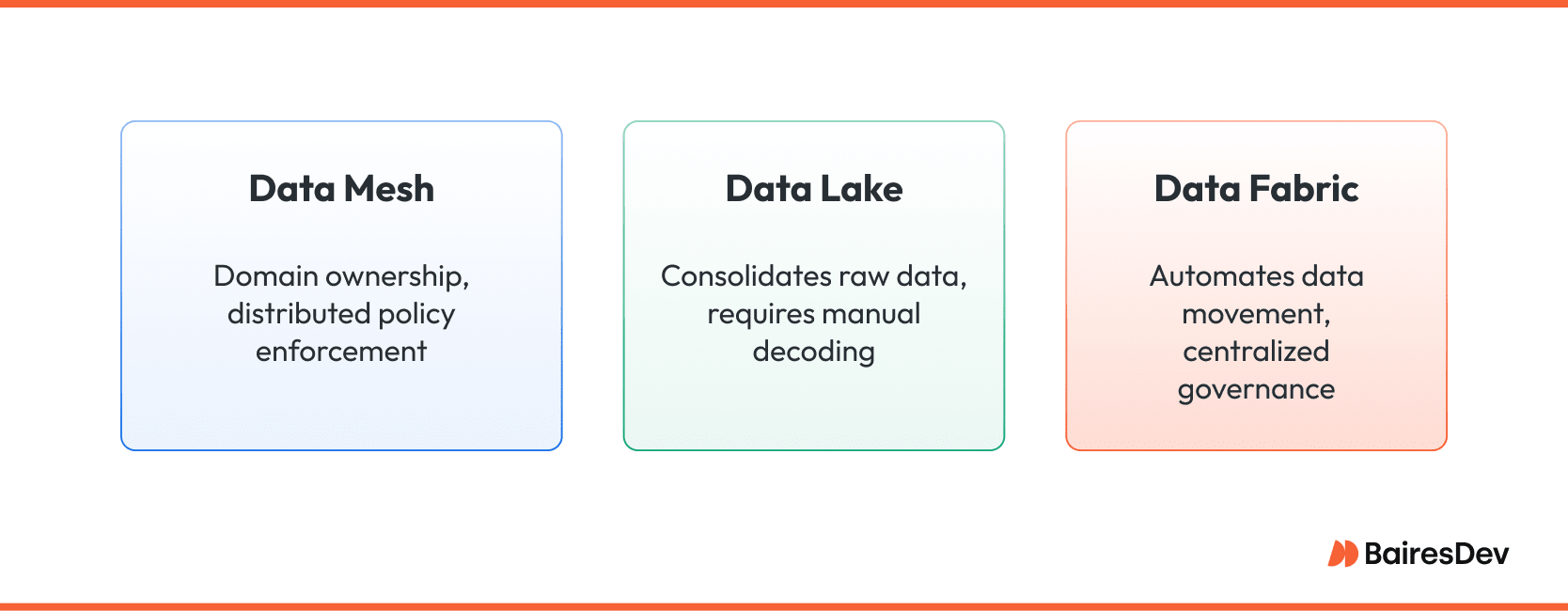
Data fabric emphasizes integration technology. It knits heterogeneous data sources into a virtual layer that feels unified to query engines. Data governance remains largely centralized, and data products are not a first-class concept. Fabric shines when the priority is automating data movement across many systems but still funnels control through one team.
Data lake strategies consolidate raw data in low-cost object storage. They scale cheaply, yet context drops as soon as files land. Analysts must decode meaning, lineage, and quality on their own. Without stringent cataloging, lakes turn into swamps that frustrate everyone except the team tasked with untangling them.
Data mesh separates itself by assigning ownership and accountability to business domains. The platform still provides data integration services, but policy and quality guardrails travel with each dataset. Consumers query data where it lives, armed with clear contracts and lineage. The distinction, therefore, is not the storage engine.
When Data Mesh Makes Sense
Mesh adoption is not compulsory for every large organization. To be a good fit, three conditions need to converge:
- The organization operates many distributed product lines that generate diverse, rapidly changing data. Central teams cannot keep pace with schema updates or domain-specific logic.
- Compliance demands are intense. Regulations like HIPAA or GDPR require clear lineage, swift right-to-delete actions, and provable access controls. Distributed data ownership shortens audit cycles because the people closest to the data handle the evidence.
- Strategic value hinges on cross-domain intelligence. Fraud detection, supply-chain forecasting, and personalized recommendations all rely on weaving multiple sources into real-time insight.
Companies still in the early stages of data maturity can delay mesh. So can teams whose analytics needs remain small and predictable. In those contexts, a well-governed lake feeds dashboards at an acceptable speed.
Mesh enters the picture once centralized data platforms stretch to the limit and decision-makers begin to wait longer for data than they do for code to ship.
How BairesDev Supports Data Mesh Adoption
BairesDev engages at every layer of a mesh journey. Senior data architects collaborate with stakeholders to map domains, identify quick-win data products, and define service-level objectives. Platform engineers then build the self-serve foundation: automated ingestion pipelines, a unified catalog, lineage capture, and policy enforcement hooks that integrate with existing identity systems.
During rollout, embedded consultants coach domain teams through product thinking. They help engineers capture metadata and publish clear documentation so other groups can adopt datasets with confidence. Code and policy move together, ensuring compliance without manual review cycles.
Finally, BairesDev measures adoption in objective terms. Usage telemetry, data quality scores, and incident metrics feed executive dashboards. Leaders see reduced time-to-insight and audit readiness improve quarter over quarter. Mesh evolves from concept to operating standard, backed by a partner that has navigated the shift across industries and technology stacks.
Frequently Asked Questions
How long does a data mesh pilot typically take?
Most enterprises see a production-ready pilot within three to four months when scope is limited to two domains and a handful of data products. Unlocking business value may take a few more months, depending on a range of factors.
Who enforces access controls without a central gatekeeper?
Data access policies sit in code, enforced by the platform. Domain owners cannot bypass them, yet they remain free to iterate on schema and business logic.
What is the biggest cultural hurdle?
Shifting mindset from ticket-driven service to product ownership. Success depends on clear incentives, executive sponsorship, and continuous education.
Do we need a data warehouse once mesh goes live?
Yes, but for different reasons. Many teams keep a data warehouse for standardized reporting, while data mesh handles decentralized, domain-owned data products. They serve complementary roles.
What does data mesh provide that traditional architectures don’t?
Data mesh enables scalable ownership. Domains maintain their own pipelines and quality standards, so teams can access data that’s closer to its source, with less delay and more context.




