


Machine learning (ML) is a part of artificial intelligence (AI) that teaches systems to extract insights and predictions from data. It uses both supervised and unsupervised learning. These cover thousands of use cases, from fraud detection to customer segmentation.
Today, 76% of companies use ML or will, and it’s changing industries. Hybrid advanced systems like semi-supervised learning and reinforcement learning can act in dynamic, input data-poor environments. Together, they expand ML’s reach and innovation.
Engineers can use these machine learning methods to process training data and find patterns in unlabeled data. Below, you’ll learn the difference between supervised vs. unsupervised learning — essential for solving real-world problems in data science and AI.
What is supervised learning?
Supervised learning is a machine learning technique that makes predictions by recognizing patterns in training data using labeled datasets. For example, in email filtering, the system learns to classify new incoming messages by looking at emails already marked as “spam” or “not spam.”
Supervised learning is good for classification and regression. For example, it can predict house prices based on size, location, and number of bedrooms. In healthcare, it can diagnose diseases based on patient test results.

Supervised learning algorithms
Supervised learning models are at the heart of machine learning. The main methods use training data for linear regression, logistic regression, support vector machines, decision trees, and neural networks.
- Linear regression: This is a basic algorithm for predicting continuous values like stock prices or weather. It minimizes error via least squares.
- Logistic regression: It’s used in binary classification tasks like fraud detection. It models probabilities with a sigmoid function that separates categories.
- Support vector machines (SVMs): SVMs separate data points into categories by finding the optimal boundary. Kernel functions extend their power to non-linear problems like object recognition in image classification.
- Decision trees and random forests: These models make predictions by splitting labeled training data into logical branches. Random forests improve accuracy by combining multiple decision trees.
- Neural networks: These are like the human brain with interconnected layers. They are good at recognizing unseen patterns in data like speech recognition or image classification.
- Gradient boosting: Gradient boosting models like XGBoost are good for ranking and predictive modeling. They are highly accurate, scalable, and can handle numerical data with basic support for missing values.
Real-world applications of supervised learning
Supervised machine learning has thousands of real-world applications, including spam detection, stock price prediction, medical diagnosis, and fraud detection. Businesses use supervised learning models to make data-driven decisions.
- Spam detection filters emails by learning from labeled examples like words or phrases commonly found in spam. Modern models adapt to changing tactics and are better at stopping unwanted messages.
- Stock price prediction identifies market trends through financial data like historical prices, trading volume, and economic indicators. These models are used for portfolio management and risk assessment.
- Medical diagnosis detects diseases like cancer with labeled test results and imaging data. Supervised learning models can improve diagnostic accuracy by finding patterns that even expert clinicians might miss.
- Customer churn analysis predicts which users are most likely to leave a service by looking at behavioral data, transaction history, and engagement levels. Companies use these insights to improve retention strategies.
- Fraud detection flags suspicious transactions by identifying unusual patterns like changes in spending habits or locations. These models adapt to new fraud schemes.
- Sentiment analysis evaluates product reviews or social media posts to gauge opinions. Businesses use this feedback to refine products, marketing, and customer engagement.
What is unsupervised learning?
Unsupervised learning is a machine learning model that trains on unlabeled data. Unlike supervised machine learning, it finds patterns in the input data. For example, it can cluster customer purchase history into segments to personalize marketing.
Unsupervised learning is best when labeling data is too expensive, especially for tasks like anomaly detection or clustering in exploratory data analysis. For example, unsupervised machine learning models can learn user preferences and behavior for use in recommendation systems.

Unsupervised learning algorithms
Unsupervised machine learning finds patterns in data. It uses unsupervised learning models like K-means, dimensionality reduction techniques like PCA, and analysis methods like association rule learning.
- Clustering algorithms
- K-means clustering groups data points into pre-defined clusters. Each point is assigned to the nearest cluster center to reduce intra-cluster variance. It’s often used in anomaly detection, where it finds clusters of abnormal behaviour.
- Hierarchical clustering creates a tree-like structure to group similar data points based on proximity. Flexible linkage criteria allow engineers to fine-tune the groupings for applications like social network analysis or ecological biodiversity studies.
- Dimensionality reduction algorithms
- Principal Component Analysis (PCA) reduces input data complexity by finding orthogonal axes with maximum variance. It is crucial for preprocessing high-dimensional datasets like image or speech recognition, where it improves computation efficiency in machine learning pipelines.
- t-SNE maps high-dimensional data into 2 or 3 dimensions for visualization to make complex patterns easier to understand. It’s great for creating intuitive clusters for tasks like gene expression analysis. t-SNE is a good visualization tool for high-dimensional data. It’s not suitable for preprocessing or feature selection because of computational cost and scalability issues.
- Association rule learning
- Association rule learning finds relationships between variables like product associations in market basket analysis. Algorithms like Apriori can generate insights like “customers who buy X are likely to buy Y.” This can be used for cross-selling and inventory optimization.
Unsupervised learning use cases
Unsupervised machine learning has many use cases like customer segmentation, recommendation systems, anomaly detection, and preprocessing for image classification. Businesses use unsupervised learning models to make data-driven decisions and improve their outcomes.
- Customer segmentation groups customers by behavior for use in personalized marketing. It can also predict user behaviour like churn risk or lifetime value. This helps businesses allocate their resources.
- Recommendation systems suggest content or products by analyzing user behavior and clustering preferences. Systems like this are at the heart of consumer platforms like Netflix. In healthcare, they power personalized treatment plans. In education, they drive adaptive learning systems.
- Anomaly detection finds outliers in financial transactions or network traffic to flag fraud or system issues. Models adapt to new threats to counter sophisticated attacks like zero-day exploits.
- Preprocessing for image classification improves features in high-dimensional data before applying supervised models. Techniques like dimensionality reduction remove noise to improve model efficiency and accuracy. They’re used in applications like satellite imaging and medical diagnostics.
Supervised vs unsupervised learning
The main differences between supervised and unsupervised learning are in their training data, goals, algorithms, outputs, and use cases. Supervised learning models use labeled data for tasks like classification. Unsupervised learning models find patterns in unlabeled data.
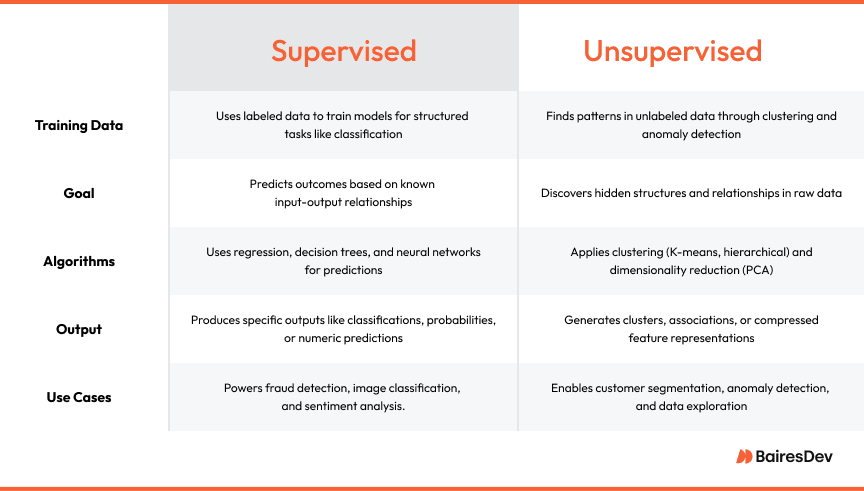
Training data
Supervised learning needs labeled or tagged data. Each input data point has to match an output data point. This pairing allows models to solve structured tasks like classification and regression. It’s good for applications like spam detection and sentiment analysis.
Unsupervised learning finds hidden patterns in unlabeled data. It’s good at data exploration, clustering data points, and finding anomalies in large datasets.
In real-world applications, supervised and unsupervised learning often work together. For example, unsupervised machine learning can preprocess unlabeled data and provide richer feature sets for supervised learning models.
Goal
Supervised learning tries to classify data or predict outcomes based on clear relationships in labeled training data. It works well in tasks like fraud detection and predictive analytics.
Unsupervised learning is about discovery. It analyses unlabeled data to find data patterns, associations, and insights. Applications range from market basket analysis to customer segmentation.
Supervised and unsupervised learning can be combined to make more accurate predictions.
Algorithms
Supervised learning uses algorithms like linear regression, logistic regression, and support vector machines. These map input variables to output to solve tasks like demand forecasting and classification problems.
Unsupervised learning uses clustering algorithms like k-means clustering and hierarchical clustering and dimensionality reduction techniques like PCA. These algorithms group similar data points, simplify high-dimensional datasets, and uncover relationships.
The difference between supervised and unsupervised learning is mainly in the algorithm. Supervised machine learning algorithms predict outcomes. Unsupervised machine learning algorithms find unseen patterns.
Output
The outputs in supervised and unsupervised learning are used differently. Supervised learning gives concrete outputs like classifications, probability scores or numeric predictions. It supports decision-making, like assigning risk scores in finance.
Unsupervised learning gives implicit outputs like clusters or associations. These guide exploration and preprocessing in responsible machine-learning workflows.
Use cases
Supervised learning is good for tasks with clear input-output relationships where the goal is to predict or classify specific outcomes. It’s good for structured tasks where precision matters.
- Image classification helps automate tasks like object detection or facial recognition by classifying labeled images.
- Fraud detection flags suspicious financial transactions by finding patterns in tagged data.
- Sentiment analysis sorts through customer feedback to gauge opinions and adjust strategies.
Unsupervised learning finds patterns or groupings in raw data. Unlike supervised learning, unsupervised learning is about discovery.
- Customer segmentation groups users based on behavior to customize offerings or marketing efforts.
- Anomaly detection finds outliers in datasets, like unusual network traffic, to identify potential issues or fraud.
- Dimensionality reduction simplifies large datasets by removing noise.
Challenges and limitations
Supervised and unsupervised learning have different challenges. Supervised models need large labeled datasets and are prone to overfitting. Unsupervised models struggle with evaluation and can misinterpret patterns because of a lack of labeled data.
Supervised learning challenges
| Challenge | Details |
| Large labeled datasets required | Supervised learning models need substantial labeled data, which can be difficult and expensive to get. |
| Overfitting risk | Complex models are prone to overfitting and will generalize poorly on unseen data. |
| Cost and time for labeling | Labeling can be time-consuming, especially in domains like medical imaging, where domain experts are required. |
| Data quality issues | Low-quality or biased annotated data can affect model accuracy and lead to unreliable predictions. |
Supervised learning needs large labeled datasets. These can be expensive, like hiring domain experts to label medical images. Techniques like active learning can help by building a small set of important data points for labeling. Developers can also use methods like dropout, L2 regularization, or cross-validation to manage overfitting. For scalable training, TensorFlow and PyTorch support parallel processing on GPUs and TPUs and can also process distributed workloads for large datasets.
Unsupervised learning challenges
| Challenge | Details |
| Evaluation without labeled data | No tagged data makes it hard to evaluate model accuracy and performance. |
| Pattern misinterpretation | Unsupervised models can misinterpret patterns and give misleading insights. |
| High computational resources | Unsupervised learning models need more computational power, especially for large datasets. |
| Clustering performance | Choosing the right clustering metric (e.g., silhouette score) is crucial for good grouping and analysis. |
No labeled data makes it hard to evaluate unsupervised models. Without the right validation metrics, unsupervised machine learning models can misinterpret noise or identify spurious correlations. To avoid this, use clustering metrics like silhouette scores and rely on domain experts to validate patterns. Unsupervised algorithms need a lot of computational power, which can slow down training. Optimized libraries or cloud-based solutions can help.
Supervised or unsupervised learning?
The choice between supervised and unsupervised learning depends on:
- Labeled data: Use supervised machine learning for structured tasks with labeled datasets, like email classification or predictive modeling. Use unsupervised learning for tasks with unstructured or unlabeled input data.
- Objectives: Use supervised methods for prediction or classification. Use unsupervised methods for exploration, like customer segmentation or anomaly detection.
- Resources: Consider the computational resources and people to label data or train unsupervised machine learning models. Supervised learning is less complex and may be better for constrained environments.
To make it simpler, hire machine learning developers who have built machine learning platforms for different use cases.
FAQs
What is the difference between supervised and unsupervised learning?
Supervised learning uses labeled data to train models where each input data point has an associated output data. It’s good for classification and regression. Unsupervised learning uses unlabeled data to uncover patterns, groupings, or structures. It’s ideal for exploratory data analysis and clustering.
Can supervised learning be done without labeled data?
No, labeled datasets are a requirement for supervised machine learning. But semi-supervised learning bridges the gap by combining a small amount of labeled data with a larger amount of unlabeled data. This is useful in fields like medical diagnosis, where labeling is expensive, but a small amount of annotated data can give meaningful insights.
Which method is better for anomaly detection?
Unsupervised learning algorithms are good at anomaly detection, especially clustering algorithms like k-means clustering. These algorithms group data points and flag anomalies. A good machine learning development company will use supervised methods like classification algorithms when labeled anomaly examples are available. This allows the model to predict specific categories.
Which industries use supervised learning?
Industries with structured data use supervised models:
- Finance: Fraud detection, credit scoring, portfolio prediction.
- Healthcare: Disease prediction, drug discovery, medical image analysis.
- E-commerce: Predictive modeling, personalized recommendations, churn prediction.
- Marketing: Sentiment analysis, campaign optimization, user behavior insights.
How does dimensionality reduction work in unsupervised learning?
Dimensionality reduction reduces high-dimensional data points by preserving the essential patterns and removing redundancy. Techniques like PCA and t-SNE transform the dataset into lower dimensions. This reduces computation time and improves visualization in machine-learning models. Lower dimensions are also better at detecting anomalies.
Summary
Supervised and unsupervised learning are the two fundamental approaches in machine learning, each with its own role. Supervised machine learning models are good for tasks that require labeled examples like classification and regression. Unsupervised methods find patterns in unlabeled datasets. That’s why they are useful for exploratory data analysis and clustering.
Both supervised and unsupervised learning are necessary for deep learning. Hybrid approaches like semi-supervised learning can solve complex problems by combining small labeled datasets with larger unlabeled data.
Choose a model that suits your project goals, data, and computational resources. Combine supervised and unsupervised.




