


Your app is a success. Users are signing up fast, traffic is skyrocketing, and revenue is climbing. But then disaster strikes. The system slows and then grinds to a halt. Software scalability measures how your system thrives or fails under growth.
Scaling isn’t just adding servers, either. Without a strategy, you’ll still hit bottlenecks. Airbnb scaled by transitioning its monolithic architecture to microservices. They wrangled surging user demand by switching to cloud hosting, but they also leaned heavily on database sharding and load balancing.
Effective software development services account for both vertical scaling (adding power to one server) and horizontal scaling (distributing workloads). Choosing the right architecture will directly affect your software’s future scalability. Tools like Apache Kafka Raw can help with high-throughput event streaming and traffic distribution.
Scaling is a marathon, not a sprint. Plan ahead, optimize early, and scale smart.
What Is Software Scalability?
Software scalability is a system’s ability to handle an increasing workload without performance degradation. A well-architected system can support more users and higher traffic without breaking down. Scalability keeps software responsive, reliable, and cost-efficient as demand grows.
There are three main software scalability types:
- Vertical scaling: Adding more computing power (CPU, RAM) to a single server for improved performance.
- Horizontal scaling: Expanding capacity by adding multiple servers to distribute the workload.
- Elastic scaling: Dynamically adjusting resources based on demand fluctuations.
Why Set Up to Scale?
Ignoring scalability in software can cause downtime, lost revenue, and user frustration as you grow. A walk through Airbnb’s architecture archaeology shows that as the company scaled, its monolithic Rails application became a bottleneck. The company sidestepped to microservices architecture to improve their scalability.
Scalability Tools
Many companies use tools like Kubernetes to automate deployment, manage resource scaling, and improve system performance under load. Here are a few other scalability tools, and how they’re used:
- Kubernetes: Container orchestration platform that auto-scales workloads based on demand, ensuring consistent deployment across environments.
- Docker Swarm: Lightweight alternative to Kubernetes for managing and scaling containerized applications in clusters.
- AWS Auto Scaling: Automatically adjusts compute capacity in AWS to maintain performance while optimizing costs.
- Elastic Load Balancing (ELB): Distributes incoming application traffic across multiple targets to ensure high availability and fault tolerance.
- Prometheus: Open-source monitoring tool designed to track performance metrics and alert on system issues in real time.
- Grafana: Visualization tool that integrates with Prometheus to build dashboards and monitor infrastructure scalability.
- Apache Kafka: Distributed event streaming platform used for real-time data pipelines and scalable communication between services.
- Redis: In-memory data store used for caching and message brokering to reduce database load and improve responsiveness.
- Hystrix (Netflix): Circuit breaker library that isolates points of access to remote systems, preventing cascading failures.
- Terraform: Infrastructure as Code tool that provisions and scales cloud resources across providers automatically and reproducibly.
Airbnb: A Case Study in Software Scalability
Airbnb learned that premature scaling can introduce complexity, but reactive scaling can cripple performance.
Premature scaling is over-engineering infrastructure or adding resources before you understand demand. It eats budget and causes unnecessary complexity and inefficient software scalability.
Reactive scaling is adjusting infrastructure only after performance issues arise. It can cause downtime, poor user experience, and inefficient software scalability under sudden demand spikes.
Airbnb succeeded by methodically restructuring their architecture, using cloud-native solutions, and eliminating bottlenecks before they became crises.
Where Airbnb Struggled (Failure)
- Monolithic Bottlenecks: In its early years, Airbnb used a monolithic Ruby on Rails application. As traffic surged, the system struggled to scale. It was plagued by longer deployment times, performance bottlenecks, and reduced developer productivity.
- Database Scaling Issues: The monolith’s reliance on a single database became a point of strain as traffic grew. It couldn’t scale, read, and write operations efficiently.
- Engineering Slowdowns: The tightly coupled architecture made it increasingly complex to make even small changes to the system. Small updates required full-system deployments, slowing software development velocity.
How Airbnb Scaled (Success)
- Architecture Archaeology: Airbnb’s engineering team thoroughly analyzed its legacy codebase. This helped them understand dependencies before they migrated to a microservices architecture.
- Service-Oriented Scaling: By breaking the monolith into independent services, they improved deployment efficiency, performance, and fault isolation.
- Kubernetes & Cloud-Native Approach: They adopted Kubernetes to dynamically scale services and optimize resource allocation.
- Database Sharding: To address database bottlenecks, Airbnb implemented sharding and distributed systems. This helped them handle traffic spikes.
- Resiliency & Load Balancing: They used traffic distribution strategies and caching mechanisms to ensure uptime even during peak demand.
Scalability Strategies: What Works and What Doesn’t
Throwing more servers at a growing system isn’t scaling. Your scalable software solutions have to work efficiently at different traffic levels. Without the right strategy, performance issues can cripple even the most promising applications. Let’s look at what works and what doesn’t.
1. Identify and Eliminate Bottlenecks
You don’t know where your performance issues are until you measure. Without proper monitoring, you can waste your software scalability efforts on the wrong fixes. Tools like Prometheus and Grafana help track CPU, memory, and disk I/O, while New Relic, Datadog, or AppDynamics pinpoint API latency and database inefficiencies.
A well-architected, scalable system needs continuous performance tracking. Airbnb used EXPLAIN ANALYZE to identify slow queries like this:
EXPLAIN ANALYZE SELECT * FROM bookings WHERE user_id = 123;
If user_id isn’t indexed, that query will force a full table scan and slow the system down. Using SELECT * pulls unnecessary data, increasing I/O. Skewed user data or outdated statistics can also mislead the query planner. Indexing, selective columns, and updated stats significantly improve performance for scalable systems.
To fix it, add indexing:
CREATE INDEX idx_user_id ON bookings(user_id);
This reduces query time dramatically and relieves pressure on the database. Airbnb also used sharding & replication to distribute read/write load across multiple databases—eliminating a major bottleneck.
Here’s a simplified workflow Airbnb followed to isolate and fix performance issues:
- Monitor CPU, memory, and I/O usage
- Measure API latency and error rates
- Profile database queries
- Trace requests across services
During software development, optimizing API response times is critical. Airbnb used asynchronous request handling to prevent slow endpoints from blocking the entire flow. They followed Site Reliability Engineering (SRE) principles to stick to smoother, scalable growth.
🔴 Common mistake: Many teams forget to monitor background jobs or queue latency, which can silently become performance-killers under load.
2. Optimize Before You Scale
More servers, more problems—unless your code is optimized first. Scaling infrastructure without fixing inefficiencies leads to wasted resources and high costs. Before investing in scalable software solutions, businesses should optimize databases, queries, and asset delivery. Caching with Redis or Memcached can drastically reduce database load:
cached_result = redis.get("user_123_profile")
if not cached_result:
data = db.query("SELECT * FROM users WHERE id = 123")
redis.set("user_123_profile", data)
As they say: cache it or crash it.
Airbnb’s software scalability issues became clear when their monolithic database buckled under traffic. They implemented indexing and query optimization, dramatically improving response times. To further cut delays, they moved static assets (like images and scripts) to Content Delivery Networks (CDNs), reducing load times globally by as much as 40%.
All these upgrades follow Martin Fowler’s teaching that scalable systems start with clean, efficient code, not by adding more hardware. Airbnb wasn’t alone in this approach. Slack and Shopify also prioritized fixing inefficiencies before scaling.
🔴 Common mistake: Over-caching without proper invalidation logic can cause stale data issues that are harder to debug than a failed server.
3. Choose the Right Scaling Approach
Scaling isn’t one-size-fits-all. Businesses have to choose between vertical scaling (adding compute power) and horizontal scaling (adding servers). Here’s a comparison:

Airbnb initially used vertical scaling, but they reached a limit. Their scalable software strategy evolved toward horizontal scaling, distributing workloads across multiple nodes. Tools like Terraform, an Infrastructure as Code (IaC) solution, helped automate and scale their cloud deployment. This marked a clear shift in mindset. “Horizontal all the things!” became the new scaling mantra.
Scaling Architecture: Building for Growth
To prepare for growth, any scalable software solution needs the right architecture. Choosing between monoliths and microservices impacts software scalability, performance, and resilience. Get it wrong, and you’ll wake up to a from-monolith-to-micro nightmare.
1. Microservices vs. Monolith: When to Switch
Choosing between a monolithic or microservices architecture is one of the biggest software scalability decisions a company will make. Monoliths are easier to build but harder to scale. Microservices offer flexibility but add complexity. Airbnb’s architecture archaeology highlights both the risks and rewards of making the switch.
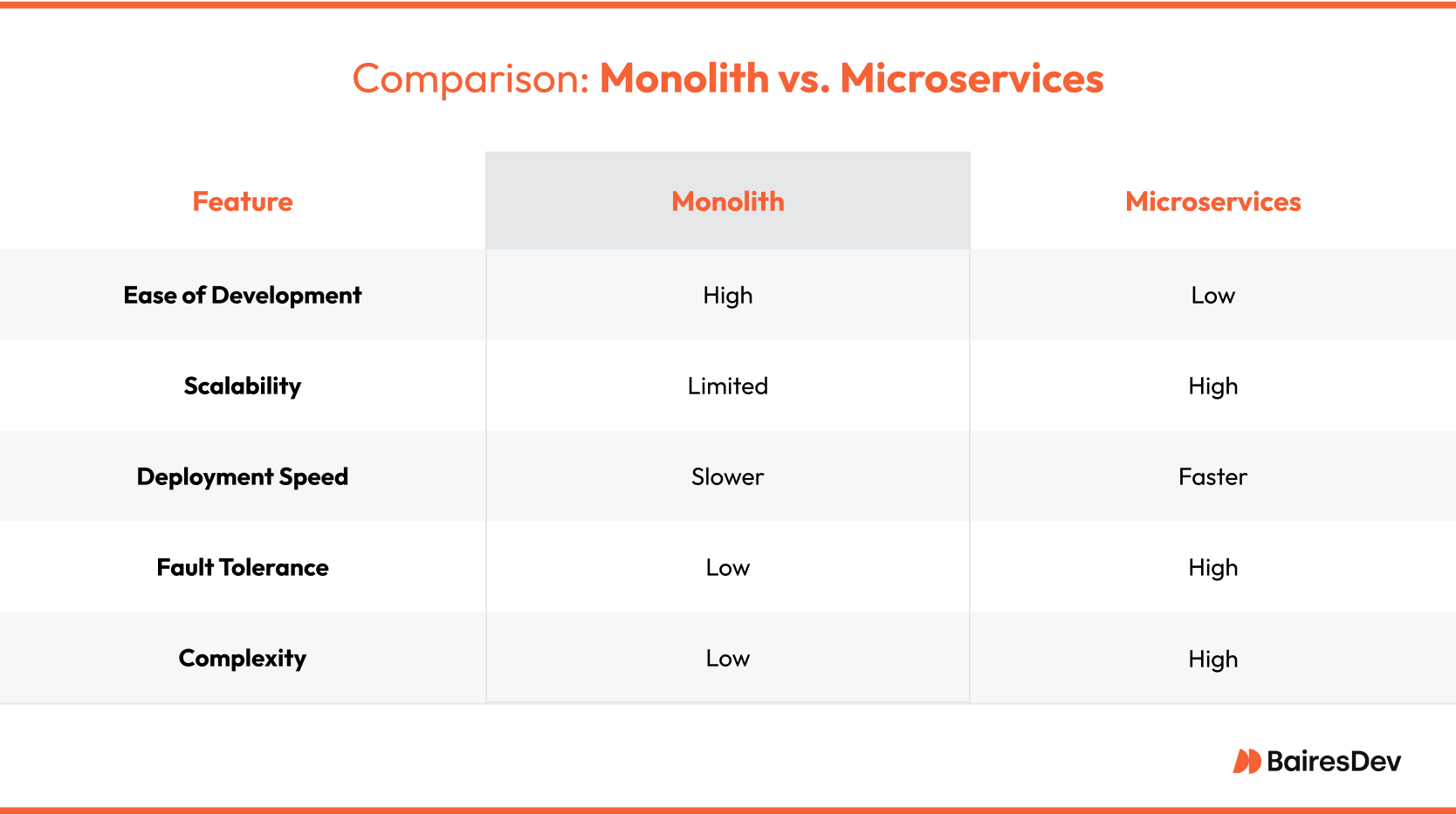
Airbnb chose a monolithic system at first. It wasn’t until their traffic started growing that they realized they’d opted for non-scaling software. They had Twitter-sized latency issues and slow deployments. Their database became overwhelmed as queries piled up. Any small change risked breaking the entire system. Transitioning to microservices architecture helped them scale, but they had to clear some hurdles first.
Netflix avoided these pitfalls by using Cloud-Native Architectures early, with Istio Service Mesh for service communication. But not every company can afford the great Kubernetes migration early on. Many choose to start monolithic, migrate services as needed, and scale or fail strategically.
2. Load Balancing
Proper traffic distribution promotes software scalability by distributing traffic efficiently. Tools like AWS Elastic Load Balancer (ELB), Nginx, and HAProxy prevent overload by spreading requests across multiple instances. Without balanced loads, even a scalable solution can crash under unexpected traffic spikes.
Key Traffic Distribution Techniques
- Elastic Load Balancing (ELB): Automatically adjusts to traffic patterns for scalable software.
- Rate Limiting & Throttling: Prevents system overload by capping API requests.
- Global Load Balancing: Directs users to the nearest server to reduce latency.
3. Database Scaling Strategies
“Sharding gone wrong.” Airbnb engineers were frustrated when their first attempt at database partitioning caused performance issues rather than improvements. Scaling software without a database strategy can backfire.
To improve software scalability, they moved from a single, overloaded database to a setup with a Write Master and multiple Read Replicas. This reduced query load by offloading reads from the primary database. Read Replicas are synchronized copies used for read operations, while the Write Master handles all writes. However, without proper traffic distribution and monitoring, some replicas fell behind in replication, leading to data inconsistencies.
Airbnb later adopted Sharding, splitting data across multiple databases to improve performance. At first, poor shard key selection led to unbalanced workloads, forcing engineers to refactor. They fixed their sharding issues by refining shard key selection, rebalancing data, automating shard management, and improving query routing.
For real-time data processing, they integrated event-driven architecture using Kafka. They ultimately ended up with a scalable solution, but their experience proved that “We’ll fix it in production” isn’t a viable scaling strategy.
Scalability Testing: Prepping for Growth
Not testing software scalability the right way before a surge in users is a disaster waiting to happen. Scaling software doesn’t just mean adding more cloud resources or simulating traffic. You can run endless load tests, but without chaos engineering tools like Netflix Chaos Monkey, you’re only proving performance under ideal conditions. That won’t build resilience for when things go sideways. Real scalability planning preps for both heavy load and unexpected failure.
1. Load Testing Before the Crisis Hits
Airbnb learned the hard way that scaling untested systems leads to failures. Without simulating real-world loads, their infrastructure buckled under peak demand, causing outages and a scramble for reactive fixes.
Proper software scalability testing starts with tools like JMeter, Locust, and k6 to simulate realistic user behavior and identify weaknesses before they go live. For instance, you can simulate 1,000 concurrent users hitting a critical API:
k6 run --vus 1000 --duration 1m script.js
Airbnb eventually adopted a Scalable Backend approach similar to Netflix’s. They stress-tested services with tools like load generators, throttling configurations, and internal chaos testing frameworks. By monitoring throughput, latency, and error rates, they tuned their services for smoother performance under real-world demand.
They also ran performance regressions as part of CI/CD, making load testing a standard part of deployment and not a last-minute scramble.
Pro tip: Don’t just test for peak traffic. Test for spikes, concurrency limits, and database contention.
2. Auto-Scaling and Self-Healing Systems
Elasticity FTW. Manual scaling burns time and budget. With Kubernetes auto-scaling, containers scale up and down automatically, so your app “just works” without constant babysitting. By shifting to containerized workloads and enabling Kubernetes Horizontal Pod Autoscaler (HPA), Airbnb scaled their compute resources based on CPU or memory thresholds.
Here’s an example HPA config:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: web-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-service
minReplicas: 2
maxReplicas: 10
targetCPUUtilizationPercentage: 75
Configs like this let Airbnb “right-size” their usage in real time, keeping cloud costs in check while boosting responsiveness. But elasticity alone wasn’t enough. The system’s ability to self-heal from failure was vital.
They adopted circuit breaker patterns (inspired by Netflix Hystrix) to isolate failing services and maintain uptime. With Prometheus and Grafana, they now track Service-Level Objectives (SLOs) continuously, ensuring issues are caught before they affect users.
Lesson learned: Without observability, elastic systems can silently degrade. “Another day, another memory leak” only ends when your platform tells you it’s leaking.
Common Scalability Mistakes
You roll out a new feature. Everything seems fine at first. Then traffic surges. Requests stack up, response times lag, and error messages start showing up everywhere. Customers get frustrated and bounce. You try throwing more servers at the problem, but the slowdown isn’t about hardware. It’s your architecture.
Good software development creates systems that minimize risks, avoid single points of failure, and perform reliably. Poor software architecture leads to scalability in software challenges that cripple growth.
1. Premature Optimization
The best is the enemy of good enough. Building for millions of users before you have 50, wastes time and money.
Airbnb didn’t start with high software scalability in mind. They chose early speed and simplicity with their monolithic Ruby on Rails app. Later, instead of jumping straight to complex scaling patterns, they focused first on improving operational efficiency. They optimized their application programming interface (API), cleaned up processing logic, and tuned their internal software for real-world use.
Their scaling strategy was measured and deliberate. They used traffic distribution software and moved toward horizontal software scalability. They broke out services only where they needed to. They simplified their cloud computing services and postponed unnecessary workload distribution. Netflix took a similar software engineering path, applying CAP Theorem tradeoffs to balance data consistency with performance at scale.
The lesson? Don’t over-engineer. Prep to scale but remember, you don’t need a global load balancer before you’ve got global users.
2. Ignoring Observability
Unseen latency issues can quietly erode performance over time. Without monitoring, issues stay hidden until they cripple performance. Enterprise software must track network latency, incoming requests, and data consistency to maintain stability.
Airbnb initially lacked a telemetry monitoring system. That led to slow debugging and undetected single points of failure. Their early mistakes show why observability is critical for better software scalability.
How Airbnb Improved Observability:
- Adopted Prometheus & Grafana: Added real-time tracking of software scaling issues.
- Implemented log aggregation frameworks: Provided centralized visibility into average response time throughput.
- Monitored cloud performance: Reduced network latency and improved response to incoming requests.
3. Scaling Software by Adding Hardware Alone
Sudden traffic surges stress every part of your stack.
A fast-growing startup rolls out a marketing campaign that brings in a flood of new users overnight. To keep up, the engineering team upgrades to bigger servers and more powerful instances. It works at first, but soon the performance issues come back. Response times lag, error rates spike, and cloud costs skyrocket. Turns out, the real issue wasn’t a lack of power. It was inefficient code, a database struggling to keep up, and a single-threaded architecture that couldn’t keep up with demand.
Cloud computing gives you rapid scaling, but poorly optimized software systems still buckle under pressure.
Airbnb started with vertical scaling. They added power to their existing server infrastructure rather than addressing architectural inefficiencies. That increased their GPU error rate cost and caused poor data integrity.
Conclusion: Scale Smarter, Not Harder
Scaling software doesn’t mean throwing more resources at a problem. Instead, design a scalable app that can handle growth. Adding servers is just compromising performance at higher costs unless you optimize your software architecture.
A well-planned horizontal software scalability strategy starts with choosing the right NoSQL databases. Then, balance cloud hosting expenses with efficient data storage. Companies like FaunaDB solve this with a distributed-first approach.
By building software systems that adapt dynamically, organizations can scale without making their existing system a maintenance nightmare. Whether you’re working with desktop apps or cloud-based solutions, scalability should prioritize systems that are reliable and cost-effective.

Scaling isn’t a Big O notation therapy session. It’s making the right choices early to avoid costly mistakes later.




