


You’ve used solid DevOps practices. Automated processes are humming. Your software development and operations teams work together like Gene Kim and Jez Humble. But as your business grows, so does the chaos. Scaling DevOps can feel like trying to shove a server farm through a Smurf tube.
DevOps initiatives that work for small teams can crumble under the weight of cross-functional teams. CI/CD pipelines turn into firewalls. Automated deployments start to need manual intervention. What used to be agile now feels monolithic. Too often, DevOps scaling comes with complexity, security gaps, and performance hits. And many organizations don’t grasp the problem until they’re deep in Yaml hell.
Let’s look at some battle-tested strategies for scaling devops practices without losing control. Whether you lead engineering teams or run a DevOps initiative, you’ll find tools and examples to keep you moving fast—without breaking things.
What is Scaling in DevOps?
Scaling DevOps is expanding your DevOps processes, DevOps tools, and culture to support more people, services, and complexity, without losing velocity or reliability. Team leaders can’t just throw more automation at the problem. They need to change how DevOps teams think and collaborate to scale with grace.
In his book The DevOps Handbook, Gene Kim emphasizes that DevOps scaling isn’t a tooling issue. It’s a culture shift. As DevOps practices stretch across larger cross-functional teams and more environments, old workflows collapse. You start seeing “Helm chart spaghetti,” “secrets sprawl,” and worse, “mean time to WTF” creeping higher with every sprint.
To avoid breakdowns at scale, teams need more than process tweaks. You need:
- Standardized DevOps processes to reduce chaos across environments
- Relentless continuous improvement to keep velocity high
- Purpose-built DevOps tools focused on visibility, orchestration, and toil reduction
- Culture changes that promote autonomy, ownership, and team collaboration
- Scalable strategies like GitOps, shift-left security, and infrastructure as cattle
When done right, DevOps scaling creates leverage—not drag.
Key Strategies for Scaling DevOps
Scaling DevOps is more than increasing headcount or buying new tools. It’s a fundamental shift in how systems are built, deployed, and maintained. As DevOps scaling becomes critical to support growing applications and teams, the right strategies can make the difference between a high-performing system and a life of firefights at 2 a.m. Below are four foundational pillars to scale DevOps effectively and sustainably.
1. Automate More
Imagine this: You push code on Friday. By Monday, it’s deployed, tested, monitored, and still green. No manual work. No frantic calls at oh-dark-thirty. That’s the dream state of DevOps automation.
Automation is the backbone of DevOps scaling. Tools like Terraform, Pulumi, and Ansible bring immutable infrastructure into play. They treat servers like cattle, not pets. With Infrastructure as Code (IaC), teams can provision environments and cut human error to the quick.
But automation can’t stop at provisioning. To scale effectively, teams also have to automate testing, deployment, monitoring, and rollback.
Core Areas of DevOps Automation
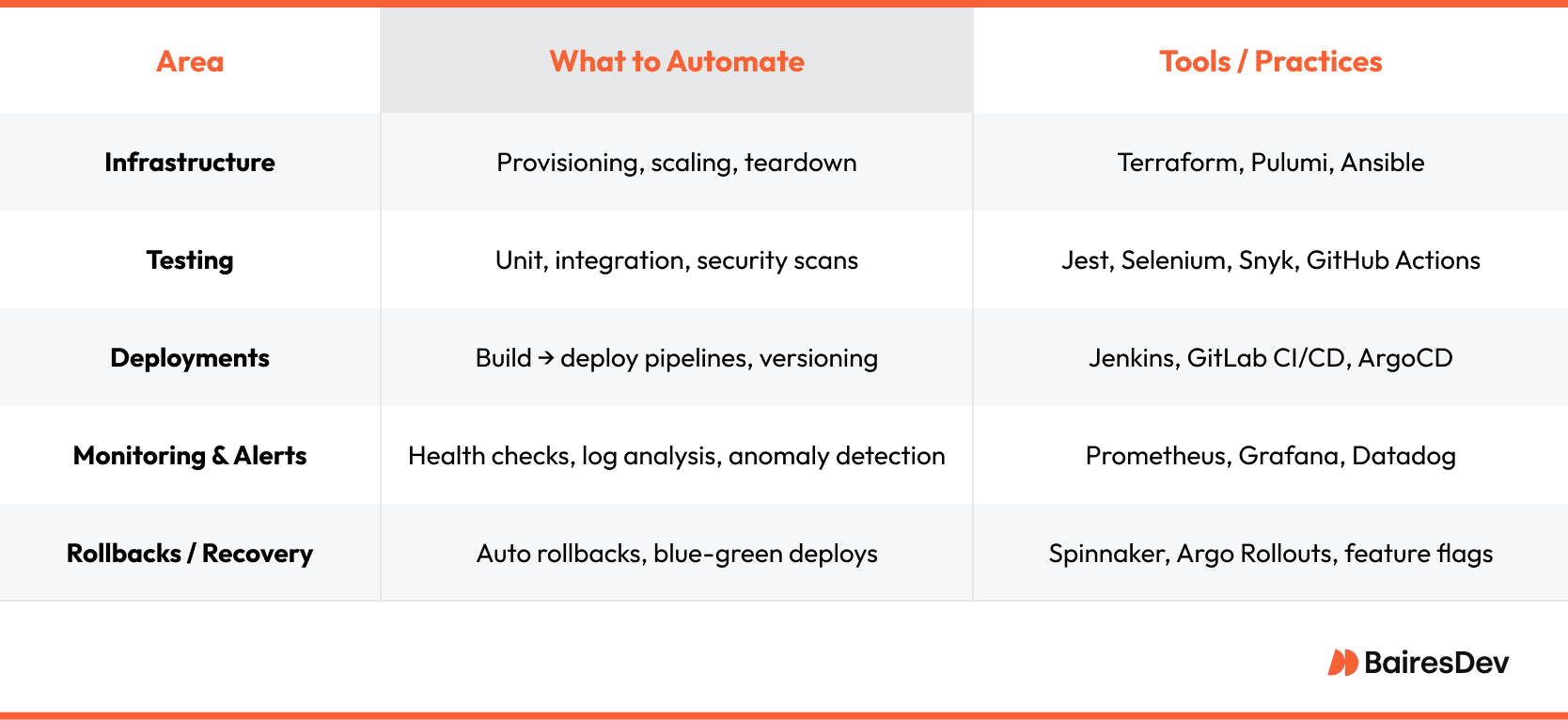
The more you automate, the less you toil. And the less you toil, the more time you have to build, ship, and scale without fear. Oh and there might be time for your life in there, too.
2. Build a Robust CI/CD Pipeline
Here’s a question. Would you rather have a pipeline that builds and tests in three minutes, or spend three days fixing things after each commit?
A smooth CI/CD pipeline is the heart of any DevOps automation. Done right, it gives you low-risk deployments without a lot of hand-cranking. Done badly, it turns into a CI/CD bottleneck where every push becomes deploy and pray.
- Adopt GitOps-first practices: Use tools like ArgoCD and FluxCD to make Git the single source of truth for deployments.
- Use Docker containers: Build in consistency and portability across all environments.
- Deploy on Kubernetes: Orchestrate and scale containerized applications efficiently.
- Implement feature flags: Control rollouts and reduce risk without full redeployments.
- Use canary deployments: Gradually release new features to a subset of users for safe testing.
- Leverage blue-green releases: Shift traffic between environments for zero-downtime deployments.
As Kubernetes evangelist Kelsey Hightower puts it: “Automation without discipline is chaos.” CI/CD must be resilient, observable, and continuously refined as teams scale.
3. Improve Observability and Monitoring
You can’t scale what you can’t see. Reactive alerts and log scraping turn day 2 operations into chaos. Observability beats monitoring every time. Move beyond uptime checks to full-context insights.
Start by aggregating logs, metrics, and traces using tools like Prometheus, Grafana, Loki, and the ELK Stack. These platforms help dev and ops teams monitor everything from service latency to deployment impact. Integrate alerts via tools like Datadog and New Relic to detect anomalies before users do.
Charity Majors, co-founder of Honeycomb.io and a pioneer in observability, says modern teams need to ask “why” not just “what.” Deep visibility helps teams reduce SRE burnout and improve their mean time to WTF, troubleshooting issues faster and with more context.
4. Grow a DevOps Culture

DevOps started as a cultural movement. That’s even more important when you’re scaling devops in a large organization.
A successful DevOps culture uses shared ownership across teams. Break down silos between dev, ops, QA, and security. Work toward a blameless environment where failure is an opportunity for learning, not finger-pointing. This cultural shift lets DevOps automation thrive.
Adopt the Site Reliability Engineering (SRE) principles from Google’s SRE Book Aim for toil reduction, service-level objectives (SLOs), and continuous feedback loops. When teams have ownership over features and operations, collaboration is more scalable.
Common Pitfalls to Avoid
DevOps scaling is essential, but it’s easy to get wrong. Former Netflix architect and cloud-native pioneer Adrian Cockcroft says scale should grow out of necessity, not ambition.
Over-Engineering
One of the most common traps in DevOps scaling is too much engineering before the team or product needs it. Infrastructure-as-code tools like Terraform and Helm Charts offer incredible flexibility. But introducing them too early can turn your scale-up into a tangle.
Automation is powerful, but if you’re automating chaos, you’re just speeding up failure. Start small, test rigorously, and expand based on actual needs. This measured approach lets large teams adapt as things scale up.
Ignoring Security and Compliance
DevOps without DevSecOps is a ticking time bomb. As deployments get increasingly complex, failing to left-shift performance and security checks can tank security. Instead, bake security into your pipeline from day one.
Use automated scanning, secrets management (e.g., HashiCorp Vault), and role-based access control. Work closely with security engineers to build a shared responsibility model, especially when you’re scaling devops across environments.
Tool Sprawl
Grasping for every new tool that promises optimization causes tool fatigue. It also welcomes the latency gremlin into your system. You’ll find yourself struggling to onboard new devs and squashing hordes of integration bugs.
Successful teams keep their toolchains tight. Staying off the “hey, we need this trendy tool” bandwagon keeps things clear and cuts down on toil.
Failing to Measure and Optimize
Without continuous measurement, there’s no continuous improvement. Teams that don’t measure can’t see themselves on the map and can’t plot a course to somewhere better.
From deployment frequency to incident response times, teams can only iterate in good directions if they monitor key metrics. Prometheus and Grafana let you visualize trends and spot issues early. They also help you dodge cloud-cost surprise by making performance and cost equally observable.
DevOps Scaling Decision Tree
If you don’t make smart decisions as you scale, DevOps turns into chaos with a CLI. You’ll feel it, too. Manual runbooks in the wee, small hours, mystery outages no one can explain, and dashboards lighting up like Christmas. Automation tools alone won’t save you. Scaling needs precision. Know when to script, what to containerize, and how to build clarity into every layer.
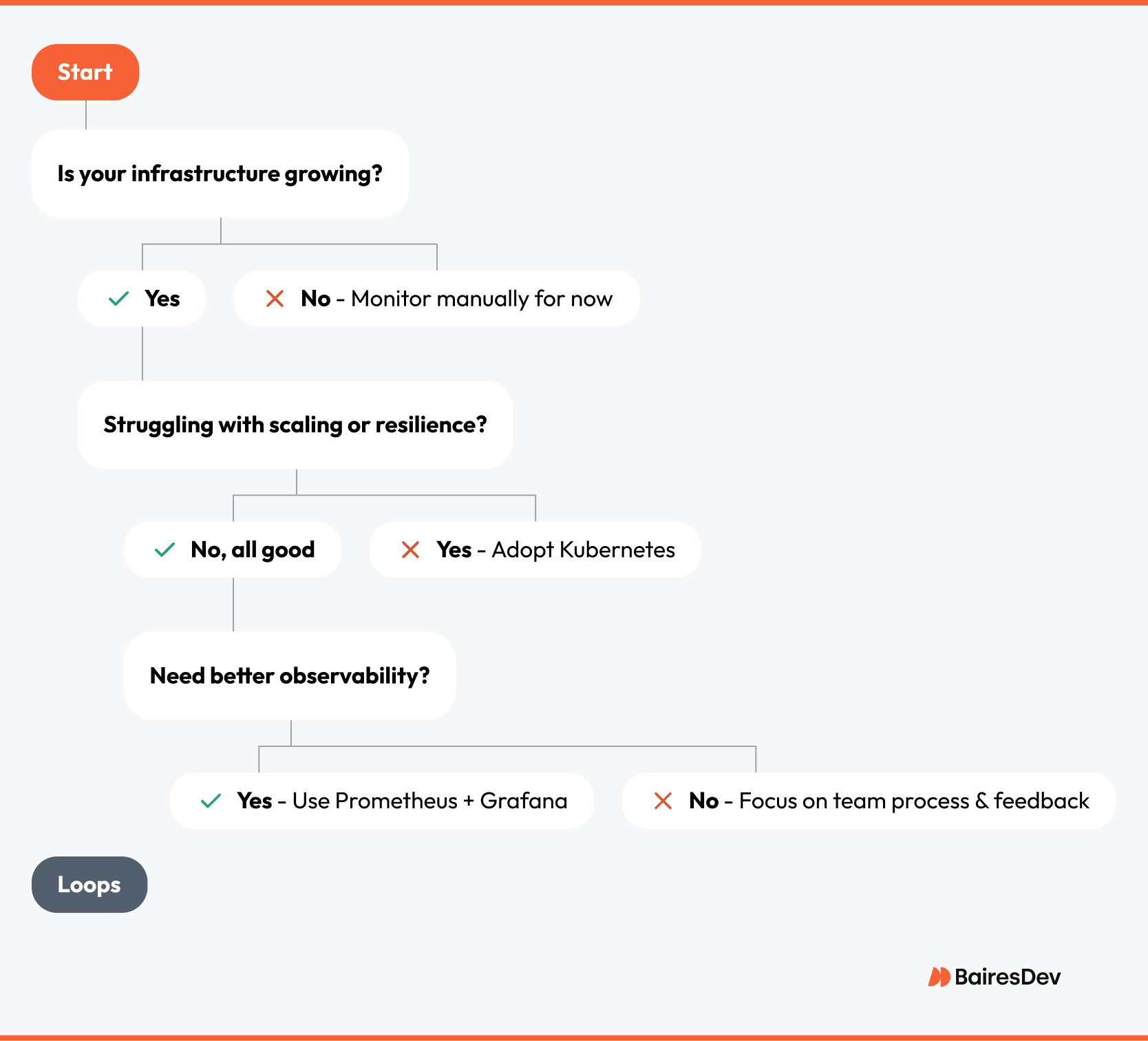
Start by assessing your team size and stack complexity. If you’re deploying across multiple environments or you have frequent outages, use Infrastructure as Code tools like Terraform to add stability. For container orchestration, weigh Docker Swarm vs. Kubernetes depending on your needs for resilience and scalability—an ongoing debate in DevOps circles.
Are your teams struggling with visibility into system performance? Then integrate observability stacks like Prometheus and Grafana. Enterprises that invest in real-time telemetry avoid “pager duty dread” and improve system reliability. Every step you take toward clarity reduces your mean time to recovery and increases confidence in production.
Scaling DevOps Isn’t One Size Fits All
To scale with grace, be intentional about your use of automation, cultural alignment, and strategic tooling. From Infrastructure as Code with Terraform to observability stacks like Prometheus and Grafana, use technologies that optimize performance and collaboration.
Enterprises that invest in cross-functional management and embrace GitOps build more reliable systems. Innovation thrives when teams iterate, measure, and adapt. Avoid the siren song of shortcuts and overengineering. Focus instead on sustainable solutions that support growth. Ultimately, DevOps scaling is a continuous journey, not a final destination. Keep evolving, keep improving.




