


Five years ago, a tectonic shift redefined work as we knew it, and it came in the form of a Large Language Model. When OpenAI released GPT-3 in June 2020, it kicked off a wave of innovation in how we work. The mix of awe, skepticism, and urgency it marked the beginning of a new relationship between humans and machines. Language became an interface, and with it, everything from coding to copywriting changed. Today, it’s hard to imagine running a business without some form of LLM working in the background, whether that’s drafting responses, summarizing documents, or guiding big and small decisions.
As software development partners to 500+ leading companies, we’ve seen how often LLMs come up in strategy sessions, roadmaps, and internal experiments. Despite all the buzz, many business leaders still feel unclear about what LLMs actually are, how they work, or what’s really possible with them. This knowledge gap should be addressed. Misunderstanding LLMs can lead to missed opportunities, wasted spend, or solutions that don’t scale. This article will give you the solid baseline you need to approach LLMs and make decisions that actually move the needle for companies.
What Are LLMs?
LLM stands for Large Language Model. These are AI systems built using neural networks, specifically transformer-based architectures trained on massive amounts of text data. That data can include everything from Wikipedia and scientific papers to social media posts and internal business documents.
LLMs are the engines behind today’s most powerful Generative AI tools. For context, Generative AI refers to systems that can create new content, such as text, images, code, or even audio, based on patterns learned from data. LLMs are a specific type of generative model designed for working with language. When you use ChatGPT, Claude, or Gemini to write an email or summarize documentation, it’s an LLM doing the heavy lifting. In fact, most generative AI applications in business today, especially those involving text, are powered by LLMs behind the scenes.
At their core, LLMs are probability machines. They are trained to predict the next word or token in a sequence. If done billions of times across billions of sentences, the model starts to pick up the underlying patterns of language, such as grammar, tone, structure, and even logical reasoning.
Tools like ChatGPT are powered by LLMs. For example, you give ChatGPT a prompt, and it generates a response that feels oddly human, sometimes even insightful. But make no mistake. LLMs don’t understand language the way we humans do. They don’t have a conscious thought process like we would experience it. They have simply become very good at guessing what sounds right based on what they’ve seen during training. Even the so-called “reasoning” models don’t reason in the human sense; they imitate reasoning by identifying and applying familiar patterns. Some researchers argue that this mimicry is all LLMs are doing, no true reasoning involved.
How LLMs Differ from Traditional NLP Models
Before LLMs, most natural language processing (NLP) systems were narrow and highly task-specific. NLP refers to the field of AI focused on helping machines read, interpret, and generate human language. Its beginnings trace back to the 1950s, but some examples you can recognize today are applications in spam filters, translation tools, and basic chatbots.
The models behind NLP tools were usually built for one job at a time. They weren’t good for multitasking. You’d have one for sentiment analysis, another for language translation, and another for extracting entities from a text. Each required large amounts of labeled data, and each had to be trained from scratch. They also didn’t transfer well across tasks. If you wanted a customer support chatbot that could both detect tone and generate helpful replies, you needed multiple separate systems stitched together.
LLMs changed that by dramatically expanding what one model could do. Here’s how:
- Scale: Older NLP models had millions of parameters. LLMs have billions, sometimes even trillions! Instead of building and maintaining dozens of narrow models, a single LLM can handle a wide variety of tasks across departments.
- Generative ability: Traditional NLP models focused on labeling or classifying text. For example, an NLP tool might flag that a customer review is negative. An LLM, on the other hand, can take that same review and generate a personalized follow-up email that acknowledges the issue and offers a solution. Instead of just identifying what the text says, LLMs can respond, rephrase, summarize, and even expand on it in natural language.
- Zero-shot and few-shot learning: One of the biggest breakthroughs with LLMs is their flexibility. You can give them a brand new task, like summarizing a transcript or turning bullet points into a social media post, and they can often do it with little or no retraining. With traditional NLP, you’d have to collect labeled data, retrain the model, and hope for decent results. With LLMs, a few examples in the prompt are often enough to get useful output.
In short, LLMs brought general-purpose language understanding into reach. Instead of building a model per task, you now have a single model that can handle many, as long as you can frame the request in language.

How LLMs Work
We already mentioned that LLMs are trained to predict the next word in a sequence. The next question is: how does that simple task lead to something that feels intelligent?
It comes down to scale and architecture. LLMs are built using a type of AI architecture called a transformer. This design helps the model understand how words relate to each other, not just individually but in context, like recognizing that the word “bank” means something different in “river bank” versus in “money in the bank.” What makes these models especially powerful is the sheer number of parameters they use. Parameters are like adjustable settings the model fine-tunes during training. With billions of them, the model can learn subtle patterns in language, which is what allows it to generate surprisingly accurate and natural-sounding responses.
During pre-training, LLMs process vast amounts of text and learn statistical relationships between tokens across long-range dependencies in a sentence or even between paragraphs. For example, in a sentence like “The project manager told the engineer that she should update the timeline,” a well-trained model learns to consider the context before deciding who she refers to. It’s not perfect, but transformer models are particularly good at tracking that kind of context thanks to their attention mechanisms.
Why LLMs Hallucinate
Pre-training gives the model a broad, flexible understanding of language. But this approach has limits, because, arguably, it learns from patterns rather than facts, so it doesn’t actually know when it’s wrong. That’s why hallucinations happen. The model generates text that looks right and sounds confident but isn’t backed by any source of truth.
This issue arises when models are asked for highly specific, niche, or factual information they weren’t explicitly trained on, or when the prompts are vague. They try to “fill in the gaps” by guessing, not by referencing a knowledge base.
To make LLMs safer and reliable for real-world use, what you can do is add a second phase: fine-tuning and alignment. This step might include supervised learning on task-specific examples, reinforcement learning from human feedback (as with ChatGPT), or rules and filters layered on top of the model’s outputs.
Even that isn’t always enough. That’s why custom training and retrieval-based methods have become essential for enterprise use. These approaches let the model access your company’s knowledge in real time, reducing guesswork and grounding outputs in actual data. Another common approach is retrieval-augmented generation (RAG). Instead of relying on what the model “remembers” from training, it retrieves relevant content from your documents or databases before answering. However, these systems are only as reliable as their underlying data sources and come with increased costs and complexity.
Even with these safeguards, some hallucination risk remains. As we said before, LLMs don’t truly “know” anything. In order to keep sytems reliable in business settings, ongoing evaluation, clear prompting, confidence scoring, and user training should be part of your checklist.
3 Types of LLMs Business Leaders Should Know
As LLMs have matured, we’ve seen a few different types emerge:
- General-purpose foundational models
These are broad, pre-trained models like GPT-5, Claude, or Gemini. They’re often offered via API and deliver solid results out of the box for everyday tasks like summarizing meetings, assisting support teams, or generating marketing copy.
They’re called foundational because they’ve been trained on massive, diverse datasets and can be adapted to many use cases. But when used as-is, they’re also general-purpose, great for speed and flexibility. On the other hand, you don’t have control over how they’re trained, updated, or deployed.
- Open-source models
Models like LLaMA, Mistral, and Falcon are freely available for businesses to run and fine-tune on their own infrastructure. They require more technical work but offer full control over data, performance, and cost.
They’re useful for industries with strict privacy or compliance needs. For example, if you work in healthcare, you might use a fine-tuned open-source model in-house to analyze patient records without ever sending data to a third-party API.
- Domain-specific or custom-trained models
These models are fine-tuned on proprietary or industry-specific data. Think BloombergGPT for finance. They’re ideal when accuracy, tone, or compliance matter, and they perform best when paired with tools like RAG or structured inputs.
Custom models are valuable when precision matters. Imagine generating compliance-ready reports in legal, drafting technical documentation in software, or answering nuanced questions from field agents in energy or telecom.
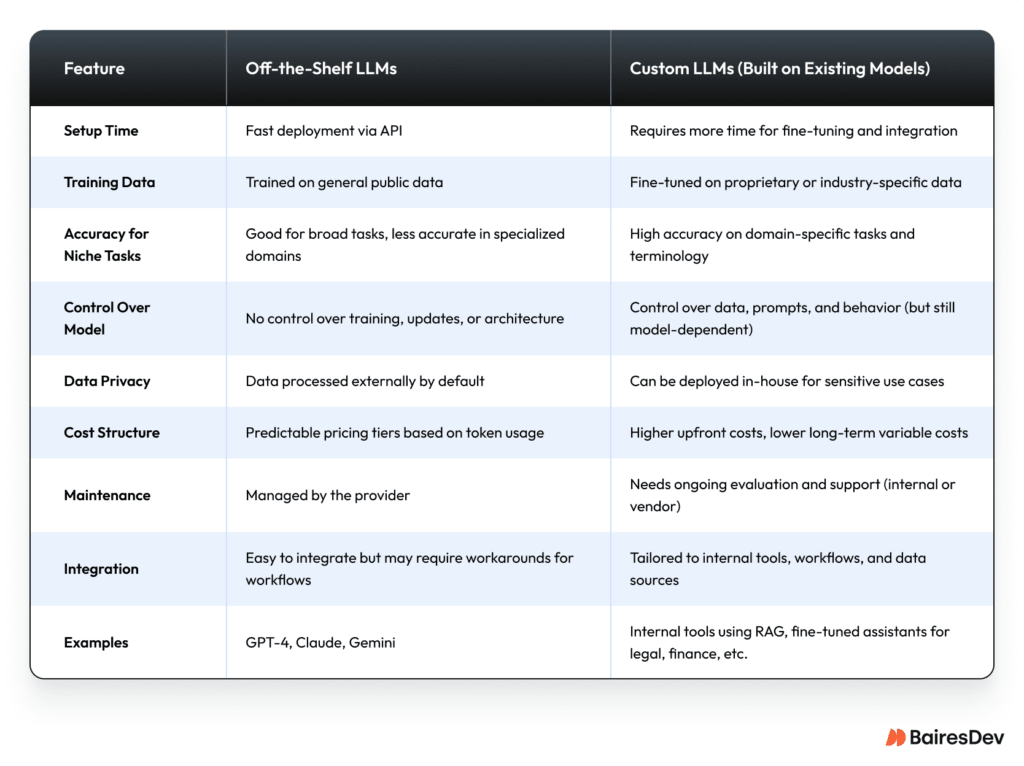
Custom LLMs vs. Off-the-Shelf Solutions
When decision-makers start exploring LLMs for business, the first strategic decision is whether to go with an off-the-shelf model or invest in a custom solution. Both approaches are valid, but they come with different trade-offs.
Off-the-shelf LLMs
Off-the-shelf LLMs like ChatGPT or Claude via API are fast to integrate. You can get a working prototype in days. You don’t have to worry about training data, infrastructure, or fine-tuning. But if your use case requires sensitivity, consistency, or specific knowledge (like legal, medical, or internal documentation), this approach has limits.
You also give up control. You’re locked into the vendor’s pricing, update cycle, and model behavior. You can prompt-engineer your way around some issues, but at the end of the day, you’re using a model trained on large-scale public data, not optimized for your business needs. This is why outputs could be generic or unreliable in critical contexts.
Custom LLMs
The term “custom LLM” can mean different things depending on who you ask. In rare cases, it refers to building a foundational model from scratch, the kind of massive undertaking done by companies like OpenAI or Anthropic. But in most business contexts, customizing an LLM means building on top of a general-purpose model (like GPT or Gemini) to better fit your specific use case. That’s the kind of LLM development work we do for clients.
This can involve fine-tuning with your own data, adapting the model’s tone, constraining its behavior, and even deploying it in your own environment. These efforts are especially valuable when you’re handling sensitive data, navigating strict compliance needs, or aiming for outputs that align closely with how your business actually operates.
You can also build hybrid systems, like using retrieval-augmented generation (RAG) to combine your knowledge base with a general model, or layering prompt templates for specific tasks. While you’re not building a model from scratch, customizing these systems still requires serious effort in data pipelines, annotation workflows, MLOps, and regular evaluation. In return, you get results that are more aligned with your business, reduced hallucinations, and better long-term cost control.
What Goes Into Customizing an LLM
Once you’ve chosen to customize a general-purpose model, the next step is figuring out which methods fit your goals the best. You don’t need to do everything at once. In fact, many teams start with prompt templates or retrieval systems and take it from there.
To ground this in reality, let’s say you run a mid-sized HR software company. You want to add an AI assistant that helps HR managers summarize employee reviews and suggest follow-up actions. Here’s how different customization techniques might come into play:
1. Fine-tuning
You start by fine-tuning a base model using hundreds of anonymized performance reviews and examples of ideal summaries. This trains the model to understand your tone, structure, and HR-specific language. You get relevant, confident outputs that reflect how your clients actually talk and work. For fine-tuning to work, though, it requires good data, clear objectives, and compute resources.
2. Prompt engineering and templates
Instead of open-ended prompts like “Summarize this,” you design structured templates: “List the employee’s strengths, areas for improvement, and recommended next steps based on this review.” This reduces confusion and helps the model deliver clearer, more actionable results. You build structured templates that guide the model toward consistent, useful outputs.
3. Retrieval-Augmented Generation (RAG)
You don’t retrain the model. Instead, you build a retrieval system (like a vector database), connecting to a database of HR policies, retention protocols, past reviews, and job descriptions. When a manager asks for a summary or action plan, the assistant pulls relevant documents in real time and includes them in the prompt. That keeps outputs grounded in your company’s actual practices.
4. Low-rank adaptation (LoRA) and adapters
You want to customize behavior without the cost of full fine-tuning. Fine. So you use LoRA to train lightweight layers that adjust how the model handles sensitive feedback language or compliance-related phrasing. It’s faster, cheaper, and easier to swap out if policies change.
5. Evaluation and monitoring
Once live, you track the model’s performance, including technical metrics like latency and token usage. You’ll track business-level outcomes as well, like how many drafts are accepted by users (HR managers), how much time they save, and whether the outputs follow internal guidelines. You’ll monitor for issues like overly generic summaries or biased language, so you can retrain or tweak prompts when needed.
If your business depends on specialized language, decision-making, or compliance, custom LLMs are definitely worth the investment. We’ve seen many teams start with off-the-shelf tools, prove the ROI, and evolve toward more tailored solutions.
A Business Dive into LLM Use Cases
Among the most common LLM implementations, there are four immediate uses that make the difference in business operations. Some of these you might have already tried, the others you should be looking into already:
1. Customer Service Automation
According to Hubspot, 77% of customer service executives report increased performance due to AI and automation, largely made possible by LLMs. They can handle routine inquiries, route emails, and support agents with live suggestions. You’ll find LLMs at work in functions such as:
- Chatbots and Virtual Assistants: Answer FAQs (like shipping, pricing, returns), guide users through account setup or troubleshooting, provide order updates, assist with password resets, and collect basic info before routing to human agents.
- Sentiment Analysis: Detect frustration or urgency to escalate cases, adjust tone based on user emotion, and surface sentiment trends to improve service.
- Multilingual Support: Offer real-time assistance in multiple languages, translate help center content, and adapt to regional slang or phrasing.
- Automated Ticketing: Classify tickets by topic (billing, bugs, feedback), prioritize based on urgency or customer tier, assign to the right agent or team, and tag with metadata for quicker resolution.
- Proactive Issue Resolution: Spot churn risks in user behavior, alert teams about recurring complaints, and suggest fixes or updates based on usage patterns.
We have first-hand experience with LLMs in this bucket. In a project for a fundraising client, our engineers refined LLM prompts to generate persuasive, emotionally resonant copy for crowdfunding campaigns. We helped boost the quality and consistency of messaging at scale across email, social, and support touchpoints.
2. Knowledge Management & Document Summarization
LLMs can comb through internal docs, emails, meeting notes, and wikis to generate clear, concise responses. This helps reduce information retrieval time across teams. Some of the most common applications are:
- Document Summarization: Generate TL;DRs for long-form documentation, highlight key action points from meetings, or simplify technical content for cross-functional teams.
- Search and Q&A: Let employees query large internal databases in natural language and get precise answers, rather than digging through folders.
- Content Organization: Auto-tag, cluster, and organize documents for faster retrieval and audit readiness.
We’ve helped clients become more efficient in this area. In one healthcare project, our engineers deployed locally hosted LLMs to process clinical trial documentation. The model helped refine user stories and functional requirements, reducing the time spent on documentation while ensuring clarity and compliance.
3. Internal Productivity (Coding, Reporting, Writing)
As a software development company, we’ve experienced how LLMs boost productivity, especially in code generation. GitHub Copilot alone is used by over 15 million developers, and 90% of Fortune 500 companies have deployed AI copilots via Copilot Studio. Alongside code generation, LLMs can draft any type of documentation your team needs, accelerating everyday workflows. Common use cases for enhanced productivity include:
- Code Assistants: Auto-suggest functions, flag bugs, and generate boilerplate code.
- Report Writing: Draft financial summaries, project updates, or client-facing documents.
- Email Drafting: Personalize responses at scale for sales, support, or operations.
For example, in one project with a medical device company, our engineers used locally hosted LLMs to refine user stories and documentation. They also implemented AI-driven unit testing to streamline development. Together, these tools boosted productivity across writing and coding tasks.
4. Compliance Review, Contract Analysis & Legal Support
According to the 2025 Generative AI in Professional Services Report by Thomson Reuters, 75% of legal professionals cite document review and 74% cite legal research as top use cases for LLMs. The ability to process dense, repetitive tasks with speed and consistency has been a game-changer for legal and compliance teams. These firms are now using LLMs to accelerate audits and reviews, improving both efficiency and risk detection. Key use cases include:
- Contract Review: Identify risky clauses, missing terms, and deviations from templates.
- Policy Audits: Analyze documents for regulatory compliance (e.g., GDPR, HIPAA).
- Legal Research: Summarize relevant case law or internal legal opinions.
We supported a finance client in building AI-powered risk control frameworks using LLMs and RAG. These solutions helped assess and mitigate risk, automate policy enforcement, and improve decision-making, all with human oversight in the loop.
Why Some LLM Implementations Fail
Not all LLM projects deliver value. Many stall or disappear after the pilot phase, and the reasons are surprisingly consistent across industries. Engineers often point to the same culprits: unclear objectives, poor data hygiene, and tools that don’t plug into existing workflows.
In other words, the problem isn’t the model. It’s everything around it. Some of the challenges you may face include:
- Hallucinations: Without proper grounding, models generate convincing but false or misleading responses. This is especially risky in legal, healthcare, or compliance contexts.
- Poor Integration: LLMs that sit outside real business workflows don’t get used, or worse, create more work than they save.
- Lack of data prep: If the model isn’t fed clean, structured, and relevant data, it can’t generate useful answers. Remember, garbage in, garbage out.
- No clear metrics: Many teams fail to define success upfront. Without usage tracking or business-aligned KPIs, it’s hard to prove ROI or even know if things are working.
- Over-reliance on out-of-the-box models: Off-the-shelf tools may impress in demos but struggle in production if they can’t reflect your business logic, constraints, or actual needs.
What to Consider Before Implementing LLMs
To avoid landing in one of the scenarios described above, our general recommendation would be to apply LLMs with clear intent and a solid foundation. Jumping in without addressing a few key fundamentals is one of the fastest ways to burn time, budget, and stakeholder trust. Here are a few basic considerations to reflect on before committing.
1. Is This Really an LLM Problem?
Not every challenge needs an LLM, even if the tech is impressive. LLMs are best suited for language-heavy, high-volume tasks, especially when they can be customized or grounded in domain-specific data. But when the problem requires emotional intelligence, deep domain knowledge, or strict regulatory compliance, even a fine-tuned model might not be enough. In cases involving low ticket volume, highly sensitive data, or nuanced decision-making, human-led processes or traditional tools may be the safer and more cost-effective choice. The key is knowing when to deploy off-the-shelf, when to customize, and when to hold off altogether.
2. Are You Data-Ready?
LLMs are only as good as the data you feed them. The old expression proves true: garbage in, garbage out. Beyond mere volume, we talk about relevance, structure, and safety. Ask your team these questions for a quick assessment.
- Do you have high-quality unstructured data (emails, documents, chats, support logs) to fine-tune or ground your model?
- Is that data accessible, permissioned, and privacy-compliant?
- Can you integrate sensitive business data securely through methods like RAG or local deployment?
If you had a hard time answering those questions confidently, take a step back and address any weak spots. LLM strategies tend to fail quickly when data is scattered, siloed, or tied up in compliance hurdles. Many companies face data challenges, and this could be your case, but that doesn’t mean you should abandon your LLM plans. Bring in experienced data specialists to help you stay on track and navigate the friction effectively.
3. Have You Budgeted for Infrastructure?
Just like everything else in life, LLMs don’t run for free. Whether you’re calling APIs or fine-tuning models locally, costs add up. Here’s what you should be budgeting for:
- Compute: Custom models may require GPUs and orchestration tools to manage inference at scale.
- APIs: Usage-based pricing means every token has a cost.
- Model updates: New versions roll out fast. Do you have a plan to test, validate, and retrain as needed?
Start small and make sure the ROI justifies the ongoing spend. For instance, imagine you’re rolling out an LLM-powered email assistant and your engineers flag an unexpected spike in API costs. It turns out prompts weren’t optimized, and no one was monitoring usage. A tighter rollout plan and usage governance would’ve saved time, and for sure, it would save budget.
4. Are You Aware of Ethics and Applicable Regulations?
LLMs bring new regulatory challenges. From data privacy to intellectual property, compliance should remain front and center in your priorities, especially in high-risk or highly regulated sectors.
Global regulation is evolving fast, with frameworks like the EU AI Act and ISO 42001 defining standards for responsible AI use. In parallel, U.S. state-level laws (like CCPA) are raising the bar on data transparency and user rights. Your business must prepare for stricter audits and accountability in the years to come.
Key risks to monitor include:
- Data privacy: Mishandling sensitive or personal data can trigger breaches or legal action.
- Bias and misinformation: Poorly trained models can produce unfair or false outputs, potentially damaging trust and opening up liability.
- IP concerns: If outputs are based on copyrighted material, you may be operating in a legal gray zone.
Overlook these points and you may be facing real business liabilities. Implement clear controls around training data, model outputs, and auditability from day one. Compliance is about earning trust and should be part of your AI strategy.
Decision Readiness Checklist

Start Smart with Pilots
When exploring LLMs, pilot programs are your best ally. Start with a low-risk, clearly scoped use case that lets you validate feasibility, integration, and ROI before committing to a broader rollout.
For instance, some companies begin by testing LLMs in marketing workflows, refining AI-generated messaging for better engagement across emails or landing pages. These use cases are lightweight, measurable, and relatively low-stakes. It makes them ideal for gauging value early and building internal confidence before scaling to more complex applications.
You may be wondering what type of specialist can jump in to support this journey. Well, we’d be the experts on that topic.
Talent and Skills You’ll Need to Succeed in Custom LLMs
Rolling out an LLM is about choosing the right models (sometimes more than one) and building the right team to make it work. One of the most common failure points in AI adoption is underestimating the human side of the equation. These systems don’t run themselves. They need people who understand not just how the models work, but also how to integrate them into business operations and keep improving them over time.
You want the following talent in your team:
- LLM engineers who specialize in integrating, fine-tuning, and optimizing large language models. They handle architecture decisions, RAG workflows, embeddings, and model performance improvements.
- Prompt engineers who can refine instructions for better outputs and efficiency. They play the role of translators between business needs and model capabilities.
- MLOps professionals who handle infrastructure, model deployment, monitoring, and performance tuning.
- Data scientists and analysts to assess the quality and value of model outputs, ensuring results are accurate, relevant, and aligned with business goals.
- Technical product managers (with AI experience) to drive strategy, prioritize features, and align development with user needs and business value.
You may not have a full in-house AI team to get started. That’s fine. What you do need is clarity to take the first steps. If you’re thinking of reaching out to specialists to augment internal teams or offload LLM development entirely, make sure to know what problem you’re solving, what success looks like, and who internally will be responsible for guiding the process.
Vendor Evaluation Criteria
If you’re partnering with an outside vendor, ask about their experience with deployments like yours. Ask how they handle privacy and model governance. Most of all, ask how they support integration and change management, because even the best LLM won’t deliver value if your people can’t or won’t use it.
For more thorough guidance, read our software development vendor guide, which includes key criteria, from technical skills to cultural alignment.
When it comes to LLMs in particular, here are a few questions for vendors to get you started:
- Do they have experience deploying LLMs in our industry or use case?
- How do they manage privacy, security, and regulatory compliance?
- What’s their approach to ongoing support, integration, and internal enablement?
Custom LLMs require partners who understand your domain, respect your data, and know how to drive business impact. Prioritize teams with real-world experience in your industry or use case. Strong partners support more than the model. They guide integration, address compliance needs, and help your teams adopt and improve the solution over time. Very importantly, you want someone who works like part of your team, bringing the right mix of engineering, data, and strategy to turn ideas into working products.
Make LLMs Work For Your Business
LLMs are powerful tools that can genuinely change how your business works. Consider the possibilities. You could be cranking out emails in minutes, catching contract issues that might have slipped by before, or getting your development pipeline moving at a pace you never thought possible. The impact is real, but only if you’re smart about how you use them.
Find the right talent and be ready to learn and adjust. The companies that are really winning with LLMs aren’t just plugging in some AI tool and calling it a day. They’re actually building their operations around these capabilities, making them part of how they do business from the ground up.




