


You know those ancient Excel files you’ve got stashed away on your hard drive? Those aren’t just digital dust collectors. They’re actually a treasure trove of untapped potential. Now, we know what you’re thinking: “But it’s old data! What good could it possibly do?” Well, just like that pile of VHS tapes in your attic, your old data can be converted and given a new lease on life.
For instance, take the 2005 sales figures for your company’s now-discontinued product line. On the surface level, it might seem like these numbers are as useful as a chocolate teapot. But dig a little deeper, and you’ll find trends and patterns that can inform future strategies.
Don’t be so quick to dismiss your old data as yesterday’s news. With the right tools and approach, you can transform that seemingly obsolete information into valuable insights that can help shape your business decisions.
You may have written it off because it’s on old hard drives, it’s unstructured, it’s literally on paper, or, even worse, it’s in a diskette as a Lotus 123 file (feeling old already?). All of that may be true, but the fact of the matter is that data is still data, and it’s a valuable asset that could be harvested for analysis or even for training a model.
That’s what we want to discuss today: how can we rescue that old data and put it to good use.
Next time you come across those dusty old spreadsheets or databases from yesteryears, don’t just shove them back into their digital drawer. Instead, think of them as raw diamonds waiting to be polished and transformed into something truly valuable (just like coal). Because when it comes to making the best out of old data, every piece of coal can become a sparkling diamond.
Interested in transforming your data into actionable insights? Learn more about our Big Data and Analytics solutions.
Cleaning That Dusty Old Data Closet: Data Audit 101
First, we need to perform a data audit. A data audit is just a thorough checkup on your data to make sure everything is accurate, consistent, and making sense. Think of it as spring cleaning for your files — you might uncover valuable insights hidden in your old data.
How do we start this deep clean? Well, we’ll begin by identifying what kind of data we have stashed away. This could be anything from customer details to sales records.
Next up is assessing the quality of our data. We need to ensure it’s reliable and relevant. For instance, if we find an old list of customers who haven’t interacted with us for a couple of decades, it might be time to let that go.
In some cases, that might mean that we also have to discard data that has been damaged. It doesn’t matter how important a folder is: if humidity destroys the contents, then it’s time to say goodbye. Take a look at a quick lesson on data quality to further understand its impact.
At this stage, it’s also important to tag your data as structured or unstructured. Don’t be surprised if you have very little or no structured data. Every data scientist worth their title knows that the world is not a structured place.
Once that’s said and done, then comes organizing and categorizing our findings. This can be as simple as sorting customer information into different groups based on their preferences or behaviors.
Lastly, we need to evaluate whether this cleaned-up data can help us achieve our goals. Is it still relevant? Does it conform to current company standards? Can it be merged with our current data? If so, what changes or conversions would have to be made?
Which brings us to our next point…
Turning Coal Into Diamonds: Techniques for Refining Old Data
As we delve deeper into our data mine, we need to equip ourselves with the right tools and techniques to unearth those hidden gems. One of these is data cleansing. It involves identifying and correcting (or removing) corrupt or inaccurate records from a dataset.
Let’s say we stumble upon a dataset riddled with inconsistencies or missing values. It’s like finding a diamond with flaws (technical term: inclusions). We wouldn’t discard it outright; instead, we would refine it until its true value shines through.
Another technique is data normalization, which adjusts values measured on different scales to a common scale. Imagine trying to compare diamonds based on weight when some are measured in carats and others in grams — confusing, right? Normalization solves this issue by bringing all measurements onto an equal footing (or scale).
Data transformation is another powerful tool at our disposal. It allows us to convert raw data (our uncut diamonds) into a format more suitable for further analysis or modeling. For instance, categorical data can be transformed into numerical data using one-hot encoding. This could be likened to cutting and polishing a rough diamond to reveal its brilliance.
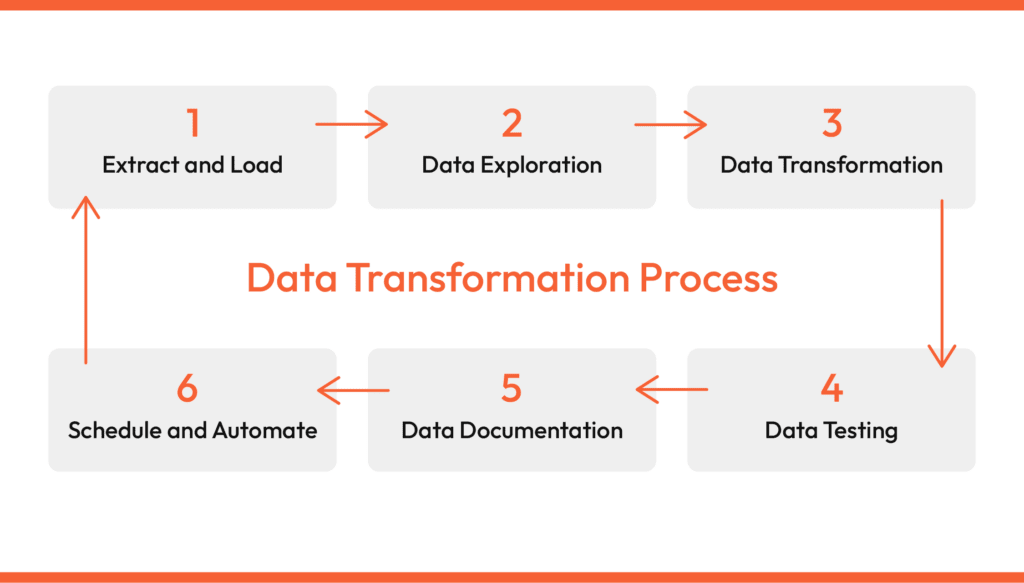
Finally, let’s not forget about feature extraction, where we identify and select the most relevant attributes from our dataset for further analysis. Think of it as choosing which facets of the diamond catch the light best.
With these methods in our tool kit, we’re well-equipped to uncover the hidden potential within even the most overlooked datasets.
The Tools of Transformation: Essential Software for Data Processing
First and foremost, there’s Excel. This trusty old workhorse is often our first port of call for data cleansing due to its user-friendly interface and robust functionality.
Of course, we also need a place to store that data, so we turn to SQL (Structured Query Language). With its ability to manipulate large datasets quickly and efficiently, SQL slices through cumbersome data with ease, enabling us to mold it into a format suitable for analysis.
SQL has a long-standing tradition as one of the most robust database technologies, which means that there are databases decades old using the same query language that modern databases use. If you’re lucky, you could do some transformation at this stage without having to resort to more elaborate technology.
When it comes to feature extraction, machine learning algorithms come into play. We use Python-based libraries like scikit-learn or TensorFlow for this purpose. Think of these as our jeweler’s loupe (a magnifying glass used by jewelers), allowing us to discern which features are most valuable in our dataset.
Privacy and Security: Safeguarding Your Old Data
In the world of data processing, safeguarding data means implementing robust security measures and privacy protocols.
First, let’s address encryption. It’s like our digital lock-and-key system. By converting data into an unreadable format (a process known as encryption), we ensure that even if unauthorized individuals gain access to our data, they won’t be able to comprehend it.
Next up is anonymization: the art of removing personally identifiable information from our datasets. This is akin to removing any unique markings from our diamonds that could link them back to their original owners.
We use techniques such as generalization (replacing specific values with a range) or perturbation (adding random noise to data) to ensure privacy while maintaining the overall integrity and usefulness of the dataset.
This is extremely important for old data files, considering that privacy concerns have changed a lot in the last decade; all untouched data from a pre-GDPR world is going to have to be combed through with a lot of care.
In essence, privacy and security are not just optional extras in our data refinement process; they’re fundamental components that guarantee the ethical and legal use of old data. After all, what good are sparkling insights if they come at the cost of privacy breaches or security lapses?

Insights and Implications: The Benefits of Leveraging Old Data
To start with, leveraging old data can lead to cost savings. Rather than spending resources on gathering fresh data, we can tap into existing datasets. This process is not only more economical but also environmentally friendly — think of it as recycling for the digital age.
Moreover, this approach allows us to uncover hidden trends and patterns that may have been overlooked initially. With advanced analytical tools and techniques at our disposal (like machine learning algorithms), we can extract deeper insights from these datasets than ever before.
Let’s consider an example from the healthcare sector. A hypothetical hospital had accumulated years’ worth of patient records. At first glance, this information seemed outdated and irrelevant. However, upon reanalysis using modern predictive modeling techniques, they were able to identify patterns in disease progression and treatment effectiveness. This rejuvenated data led to improved patient care plans and significantly reduced healthcare costs.
Not only does leveraging old data save time and money, but it also uncovers gems of insight that can transform business strategies or even save lives.
Conclusion: Embracing the Diamond Mindset in Data Utilization
In our pursuit of a sustainable and continuous use of old data, we’ve unearthed its potential to be more than just dormant bytes in storage. We’re looking at a treasure trove that can provide valuable insights and inform decision-making processes.
We need to adopt what we call the “diamond mindset.” This mindset is all about seeing beyond the apparent obsolescence of old data and recognizing its enduring value.
It’s about nurturing sustainability and ensuring continuity in our data utilization practices.
To sum up, embracing the diamond mindset means seeing old data as a valuable asset that holds immense promise for future growth and innovation. While we may still be in the early stages of understanding its full potential, one thing is clear: in our data-driven world, every file and every hard drive is a potential diamond mine waiting to be discovered.




