
The IBM team incorporated Urban Dictionary to expand Watson’s vocabulary. It seemed like a good idea, but Watson couldn’t figure out when to appropriately use slang. Watson’s responses were weighed down with inappropriate colloquialisms, and they had to bid farewell to UD. This incident highlights the AI white elephant in the room: we haven’t given generative AI the input to navigate the intricacies of cultural diversity.
We are fully distributed at BairesDev. Our team is split with about 35% in Brazil, 20% in Mexico, 20% in Colombia, and the rest in over 40 countries. We need generative AI to be culturally fluent so our workforce can use it effectively. How do we create an environment for our talent to thrive? We arm our team with the tools to be productive and creative, and at this moment, GenAI falls short.
Let’s explore why we need to:
- Change the data we input so we can use generative AI for decision-making
- Provide additional cultural context in user-generated content
- Improve the cultural fluency of machine learning trainers.
Feed GenAI Representative Data to Make Better Decisions for Multicultural Societies
AI broke ground in predictive analysis and forecasting. Our team has worked on AI projects for our clients that go from strategic marketing projects to forecasting accurate delivery times with weather and traffic data, or even building algorithms to reduce the cost of fertilizer. Yet, GenAI is a leap forward. It generates new ideas informed by data and logical reasoning.
Take, for example, converting a portrait image of a dog sitting on the lawn into a square one. In the conversion, grass will be missing to the right and left of the dog. Instead of asking a graphic designer to add grass to the picture, you can turn to GenAI, which can generate new grass in the image. No more cutting and pasting; generative AI excels at improvisation.
We can use GenAI to churn out novel ideas and simulations so leaders can make better decisions. But those simulations need representative data, like the grass in the dog’s photo. GenAI doesn’t have to imagine what grass looks like.
Using GenAI Simulations for Smarter Education Investments
GenAI can simulate a 20-year plan for resource allocation that improves literacy in underserved areas. The first step would be to input data such as exam grades, predominant mother languages, income levels, and even the region’s library density. With this information, AI can project the impact of targeted changes or even suggest the changes on its own!
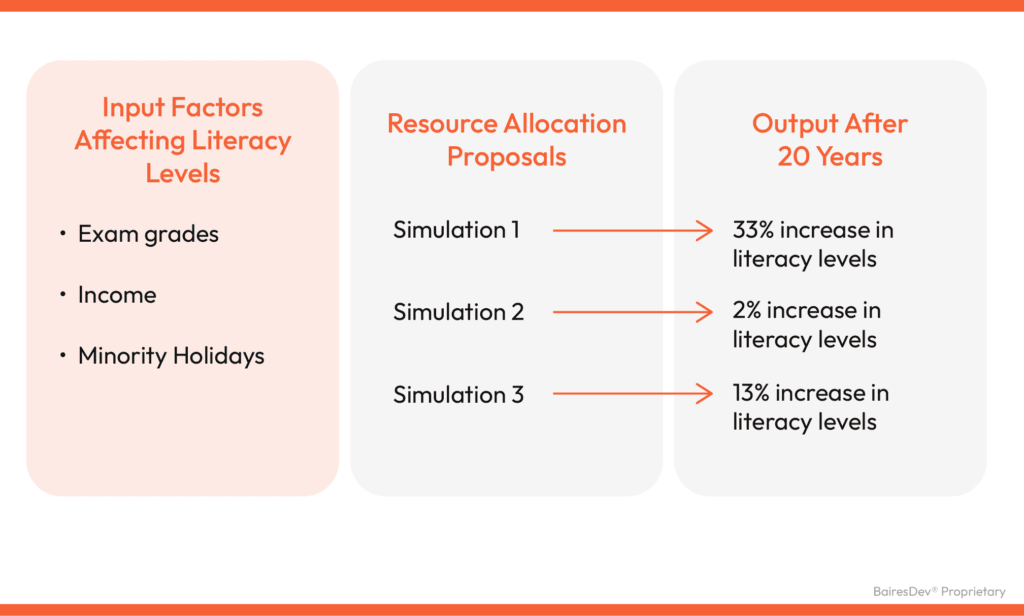
We don’t have to guess and experiment with a generation of school kids. To ensure accurate simulations, we need to feed GenAI systematically and fairly.
An illiterate person may not directly feed natural language processing (NLP) algorithms their challenges. They might not even be aware of them. Instead, we could input kids’ grades, cultural backgrounds, and culture-specific details, like holidays. We can also include text from parents of similar backgrounds.
The result? A child might not know how to write persuasively because:
- Schools teach persuasive text during a minority holiday (i.e. Holy Week, Diwali).
- The parents speak a Semitic language at home, not English.
- The instructor isn’t knowledgeable about the pupil’s source languages.
- The textbooks have been out of stock in local bookstores.
- The buses from a particular neighborhood are consistently late every morning, making them arrive late for their writing sessions.
Input in all those problems and GenAI will recommend resource reallocations like increased library funding, targeted grants, diverse staffing, or culturally sensitive curriculum. Lastly, we can use GenAI to simulate the 10-year outcomes of these resource initiatives, enabling informed decision-making.
AI Needs to Know Who Is on the Other Side of the Screen
GenAI builds on its interactions. ChatGPT has around 180.5 million users, resulting in billions of interactions and counting. Its major failure is that it stumbles on accuracy. Those inaccuracies are grounded in these untallied interactions.
For instance, I asked ChatGPT to come up with 10 titles for this article. It replied with 10 that all employed colons — apparently, colons in titles are trending! I wanted something more concise and asked for titles without them. It took ChatGPT four attempts to get the instruction right.
Was it confused like a human? It’s supposed to be a grammar whizz. Or is it sifting through millions of conversations with users that are splattered with inaccuracies due to our collective struggle with colons?
The key to improvement lies in AI’s awareness of its conversational partner. With such awareness, it can discern when to absorb and share information with others.

Take Advice From the Right Source
When I ask my tennis coach about perfecting backspin on a stroke, I take his advice to heart. If he turned around and told me to invest 80% of my stocks in an e-commerce startup, I’d take it with a pinch of salt. We assess the validity of opinions and information on who’s sharing them.
When we simply let AI loose with millions of users’ interactions, that data is compiled into a mess of uncategorized material. To enhance AI accuracy, users should have a means to voluntarily share key information like native language, profession, qualifications, location, and age. As humans, we gather endless observations on those around us until we trust them to influence our decisions.
It’s the basic argument of grounded and ungrounded opinions. Grounded opinions, like medical advice from a doctor, hold weight. Ungrounded ones, such as a cab driver diagnosing appliance issues, are taken with a grain of skepticism.
To reduce AI inaccuracies stemming from user-generated content, we must incorporate a secure way for users to share personal information without compromising data privacy. With more representative data and context, the next step is to focus on culturally adept NLP engineers and machine learning developers.
Diverse AI Trainers Need to Collaborate With Cultural Fluency Advocates
Immigrants have a knack for entrepreneurship. There’s something special about mixing in external views to fill market gaps. The National Foundation for American Policy found that of 582 US startup companies valued at $1+ billion, 55% were founded by immigrants.
My co-founder Paul and I identified a need for engineers in the US from our base in Buenos Aires. Our success lies in our developers’ fresh perspectives, resulting in a remarkable 95% net promoter score. They solve problems in novel ways, thinking beyond conventional approaches.
GenAI relies on our input and our instructions. Its training comes from our data scientists. Data scientists, including natural language processing engineers and machine learning experts, shape its capabilities, such as ChatGPT’s humanlike interactions or Adobe Firefly’s image generator.
The teachers you remember involved storytelling in their lessons. Stories show you how something works. How do you teach a four-year-old division? Cut up a pizza and give a piece to each family member. Similarly, generative AI must be equipped with comprehensive data inputs, diverse examples, and adaptable teaching styles to serve a multicultural society.
We need diverse devs training AI algorithms, and lots of them. As a caveat, I argue that we can’t burden our machine learning devs with single-handedly teaching GenAI how to be culturally fluent.
Collaboration with researchers or anthropologists to train AI on different cultures is essential. After all, 0.8% of Brazil’s population is indigenous, and yet (for the most part) they aren’t users of AI or software developers. Someone external needs to step in to teach AI about minority cultures, especially if GenAI is to be used to make policy decisions and allocate resources. Diverse educational backgrounds contribute distinct perspectives to AI training.

Culturally fluent generative AI is essential for our engineers to make products and innovative solutions that thrive in a global economy. It’s not just about personalization; it’s about ensuring AI understands and respects cultural nuances. What if you could only use Google if you knew code? All the advances Google brought in the realm of information accessibility and efficiency would be erased.
We need to make sure our AI inputs — both manual and user-generated — are culturally diverse and contextually relevant. Navigating cultural diversity has been a feat for humans. Can AI assume our gaps and failures by becoming culturally fluent?




