

In 2024, at least 10 major cybersecurity attacks have rocked various industries. From healthcare to finance, no sector is immune. As attacks evolve, so do the risks. With vast amounts of data flowing through systems daily, the sheer scale creates a tempting target for hackers looking to exploit this information. Research by ThoughtLab shows it takes an average of 128 days to detect a breach (pg 66), giving hackers plenty of time to wreak havoc. In healthcare specifically, the cost of falling victim to a data breach is estimated at 10 million in 2024. This relates to the indirect costs of regaining customer trust, which can be a relentless uphill battle. With breaches taking so long to detect and the costs of an attack so high, there’s a dire need to take a more proactive approach to cybersecurity.

Building digital immunity is an ongoing effort. Let’s examine practical ways to bolster immunity through software supply chain security, observability, and site reliability engineering.
What Is Software Supply Chain Security?
Nobody is building their product entirely from scratch anymore. Custom code might be written for unique features or proprietary systems (like Apple’s iOS operating system), but the building blocks of most software are reused across the industry. Modern software is a mix of proprietary code, third-party libraries, open-source components, and vendor solutions. It’s how streaming services integrate payment gateways like Stripe, and SMS notifications are sent to your account (triggered by platforms like Twilio).
Modern software products are a patchwork of inventions, so as a default, you rely on the integrity of someone else’s development, maintenance, and security. However, you don’t have to wait for an inevitable breach outside your sphere of influence. You can set up defenses by vetting vendors and safeguarding against their mistakes or relapses. These strategies amount to your software supply chain security.
Why Make Software Supply Chain Security a Priority?
A weak link in your software chain can topple everything. Software supply chain security is like locking a house. You might invest in an expensive smart lock on the front and back doors, but forget to shut the bathroom window, which becomes an entry point for intruders. Similarly, delaying a software update can allow a virus to infiltrate and spread across the whole digital system.
For example, the MOVEit Transfer tool, widely used for securely sharing sensitive files, became the target of a significant supply chain attack in June 2023. The breach impacted 620+ organizations, including the BBC and British Airways. The frontline of defense, in this case, MOVEit, must do the utmost to prevent attacks, as should the rest of the army, meaning their users.
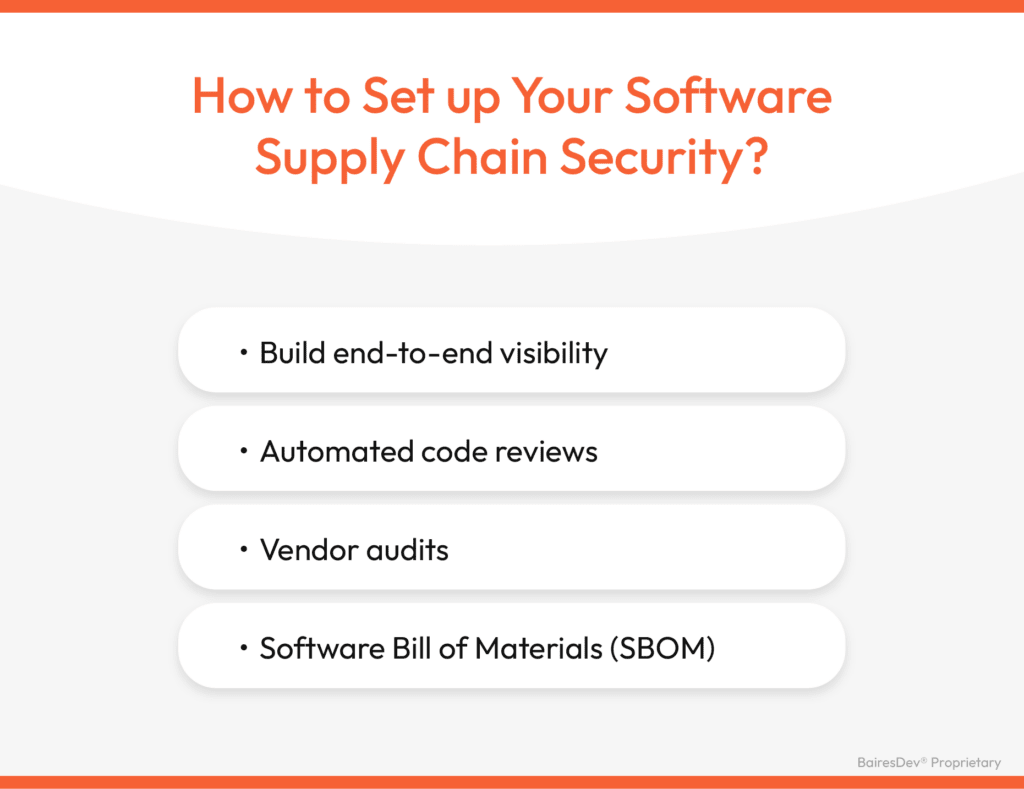
How to Set up Your Software Supply Chain Security?
Every supply chain component must be tracked, verified, and secured to avoid weak spots. Consider the following practices for your software supply chain security.
- Build end-to-end visibility by mapping every entrance and exit in a software village. Knowing the risks and entry points is the first step to securing them.
- Prioritize attack surface reduction to minimize the number of potential entry points by eliminating unnecessary services, ports, or software that could be exploited.
- Automated code reviews are faster and more consistent than manual code reviews, much like how modern cars use sensors to monitor engine performance and alert you to issues long before you notice them manually. When dealing with thousands of lines of code, automated reviews are essential for efficiency.
- Vendor audits make sure your partners are up to scratch. Third-party software is like subcontracting parts to build a car. You should quiz vendors on how they handle sensitive data (proper encryption, data storage, access control procedures, compliance with GDPR or HIPAA).
- Software Bill of Materials (SBOM) documents every software component, from open-source libraries to third-party plugins. With an SBOM, you can trace every piece of code back to its origin, so when a vulnerability is discovered, you’ll know exactly where it is and how to fix it.
What Is Observability in Cybersecurity?
Observability is a real-time surveillance system that pinpoints early warning signs. It detects unusual spikes in traffic, unauthorized access attempts, and unexpected behavior in your systems. Observability lets you catch anomalies before they turn into full-blown security incidents. Your team should use these tools to monitor data across your infrastructure and turn that raw data into actionable insights.
For example, a retail company might notice a sudden surge in traffic during non-peak hours. At first glance, this could seem like positive growth, but through observability tools like Prometheus or Grafana, the team could discover that this spike is coming from repeated access attempts to the payment gateway. With this insight, they can swiftly block unauthorized traffic and prevent a potential breach.
Why Make Observability a Priority?
Observability is like installing motion sensors across your infrastructure. It ensures that even the smallest disturbance is detected before it snowballs into a full-blown disaster. Like a fire alarm that goes off before the flames spread, observability tools alert teams to unusual activity, allowing for rapid incident response. The faster you detect an issue, the quicker you can address it—minimizing downtime and protecting your operations.
Netflix is an example of why observability pays off. With 260+ million users on hundreds of devices/smartphones, it faces a momentous challenge to offer seamless viewing experiences to all of them. But there is a reason it won the highest user satisfaction percentage, 36%, among the main streaming platforms: they invest big in keeping streaming seamless.
Let’s look at some of Netflix’s hallmark observability tactics. Storing every log from their growing ecosystem quickly became unsustainable, both in cost and speed. To solve this, Netflix built Mantis, a real-time stream processing platform that filters, transforms, and stores only the most relevant logs based on specific queries. With Mantis, they can zero in on key issues—like isolating playback errors on specific devices—without being overwhelmed by unnecessary data.
Beyond logging, Netflix also implemented distributed request tracing to gain visibility into the thousands of microservices powering its platform. By tracing and analyzing complex requests across services, Netflix can uncover issues buried deep in its infrastructure, allowing engineers to pinpoint and resolve problems in record time.
You want to mirror Netflix’s dedication to observability to give your team the power to catch threats quickly. You’ll face small disruptions instead of full-scale failures.
How to Amplify Your Cybersecurity through Observability?
Observability is having eyes and ears on every corner of your network, then making sense of what you see and responding quickly. Here’s how you can step up your cybersecurity game with observability:
- Automate anomaly detection and threat analysis. We now have the tools to set up our own digital security guard who never tires of spotting unusual patterns in your system because he never sleeps. Many companies, like Darktrace, use AI to recognize patterns too complex for humans to detect, acting as digital watchdogs.
- Correlate data from multiple sources. Catching a security issue is only half the battle—you must trace it back to its root. It’s like finding a leak in a dam; the water level is receding, but the crack could be anywhere. By correlating data from various logs, metrics, and network traces, you can piece together a full picture and pinpoint where the problem started. This way, instead of plugging holes, you can fix the underlying issue.
- Use tools Like Splunk or Datadog for real-time monitoring. These tools work like a command center of screens that track movements in your system. They act as your virtual control room, flagging unusual activity, performance degradation, or any suspicious behaviors as they happen. Whether it’s a sudden drop in performance or unexpected traffic from an unknown source, these tools keep you one step ahead.

What Is Site Reliability Engineering?
SRE focuses on automation to reduce human error, factoring in an error budget to prevent unprepared feature releases. It also ensures the reliability, scalability, and performance of systems to prevent downtime.
For example, SRE balances reliability with innovation through an error budget. You couldn’t half-test the first airplane flight—it either flew or didn’t. However, the pilot could set up safeguards to minimize disaster. Similarly, the error budget ensures that introducing a new feature (the beta version) won’t destabilize the system. At its core, SRE is a proactive approach, like wearing a parachute and helmet on a test flight—preparing for the unexpected while pushing forward.
Why Make SRE a Priority?
SRE practices like factoring in an error budget put up safety nets so your innovation is incremental and sustainable. It’s like expanding a fence a few feet to let you explore rather than removing it completely. SRE should be a priority to prevent general chaos if there happens to be a flaw in a release.
When Nike attempted to modernize its global supply chain by implementing advanced planning software called i2, things went haywire. The system lacked the flexibility to handle real-world complexities. The failure resulted in inventory mismanagement, with some products being overstocked and others understocked, leading to up to $100 million in losses. Unveiling software on such a scale, no matter how confident your devs are in their performance, is not a good idea. Properly enforced SRE could have set up an incremental plan to release i2.
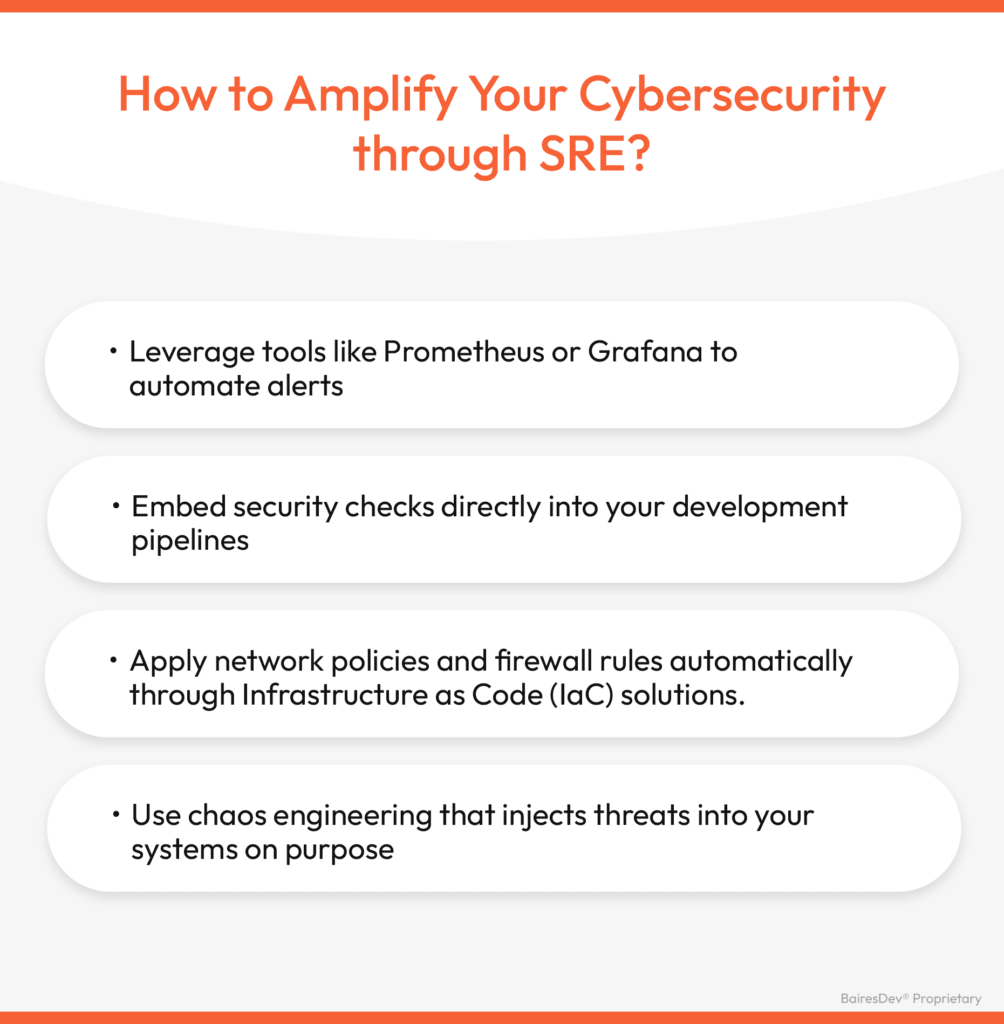
How to Amplify Your Cybersecurity through SRE?
We’ve developed a proven Site Reliability Engineering (SRE) checklist that has consistently helped clients minimize risk while scaling their operations.
- Leverage tools like Prometheus or Grafana to automate alerts when security thresholds are breached. Instant notifications let your team react swiftly to potential vulnerabilities.
- Embed security checks directly into your development pipelines with DevSecOps. Tools like SonarQube or Snyk can be integrated into your CI/CD workflows to conduct real-time vulnerability scanning or code analysis. This way, your code is continually being assessed for security flaws before it gets deployed, reducing the chances of a breach.
- Apply network policies and firewall rules automatically through Infrastructure as Code (IaC) solutions. Terraform or AWS Cloud Formation can ensure your security configurations are applied consistently across all environments. This eliminates the inconsistencies generated by manual processes, helping you maintain a uniform security posture.
- Use chaos engineering that injects threats into your systems on purpose to see how they will react. It’s like sending firemen into controlled fires as part of their training. Netflix’s famous Chaos Monkey, for example, randomly terminates services in production to test how well the system handles failures. By deliberately injecting failure, you can proactively identify weak spots in your architecture. Building the instincts and skills needed to deal with actual threats is easier if you know what to expect.
Conclusion
Cyber attacks are inevitable, but with the right strategies—like software supply chain security, observability, and Site Reliability Engineering (SRE)—you can significantly reduce your risk. Whether it’s through automated alerts, real-time monitoring, or testing your limits with chaos engineering, these strategies help ensure that small issues don’t turn into major disruptions. By adopting these proactive strategies—just as Netflix safeguards its operations and Nike could have prevented costly missteps—you can protect your systems from the unexpected while driving innovation forward.




