


The market is saturated with AI options, and narrowing down the right fit for your software development team or product can get overwhelming fast. Plus, the trickiest part is that the most meaningful insights often only surface once you’ve deployed a system and seen how it performs in context.
In this guide, we’ll focus on OpenAI Pro—what it includes, how it works, and how it compares to Claude, Gemini, Mistral, Llama 3, Command R, and Grok in real-world use.
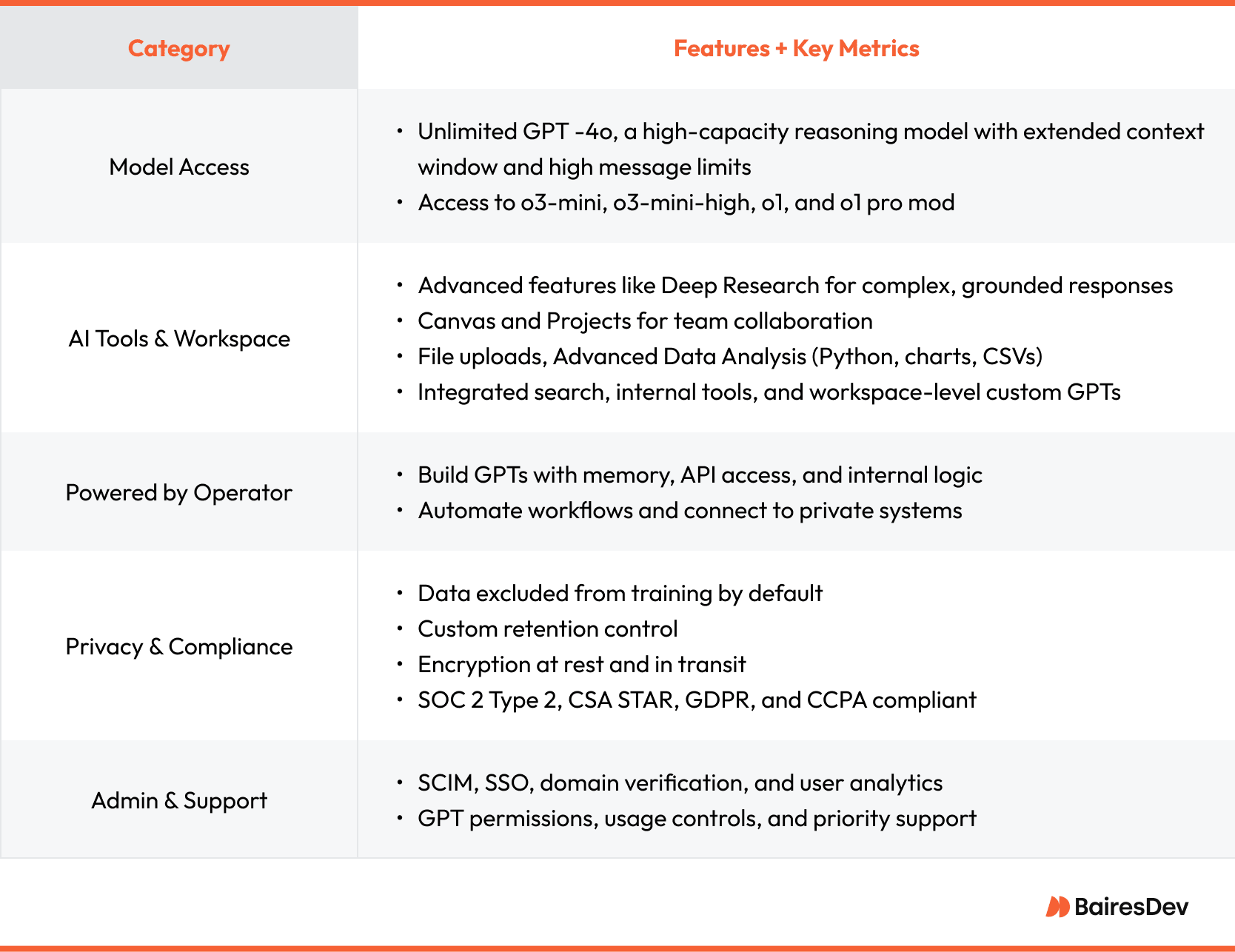
What is OpenAI Pro?
Let’s get one thing straight—“OpenAI Pro” isn’t an official product name. It’s just a casual way most people refer to the $200/month ChatGPT Pro subscription. This one, though, is built for individual users. If you’re a company, you’d be looking at the Enterprise tier instead, as PwC and Klarna are already doing. That gives you way more GPT-4-turbo usage than Plus or Team and includes paid access to everything in Pro along with admin tools, SSO, usage tracking, and locked-in security and privacy. Pricing is custom, worked out case by case.
ChatGPT Enterprise
The table below gives a quick overview of what ChatGPT Enterprise is built on:
Two Crucial OpenAI Pro Capabilities: Operator and Deep Research
OpenAI Pro Operator and Deep Research are two of the most important capabilities in ChatGPT Enterprise. They take the model from just answering questions to actually running logic, pulling live data, and connecting directly with real business workflows.
Operator API
Operator is a web execution agent that’s one of OpenAI Pro’s most forward-leaning tools, although still very much in the early stages. It interacts via its own browser context and is capable of performing task-level automation by directly interacting with live web interfaces on your behalf.
This means it can click buttons, fill out forms, scroll pages, and submit data like a human user would. You assign it a goal, and it executes, whether that’s ordering supplies, submitting a report, or handling repetitive workflows that usually burn hours of manual effort.
Deep Research
Deep Research is OpenAI Pro’s tool that’s been built specifically for long-form, high-effort tasks, more specifically ones that go well beyond basic prompts. While GPT models can answer questions, summarize documents, or help with content generation, Deep Research is designed to conduct full-scale research workflows independently.
You might ask it to compare vendors, map out a competitive landscape, run math-based risk models, or analyze regulatory exposure. From there, it would run the full process that would involve searching online sources, pulling structured and unstructured data, and handling complex reasoning tasks across PDFs, spreadsheets, and web content. And throughout the task, it would log every action and cite each source, so when you get the final report, you know exactly how it got there and can rely on the output with confidence.
AI Model Comparison: ChatGPT Enterprise vs. Other LLMs
The large language model (LLM) ecosystem has expanded rapidly, with different models now optimized around different priorities. Some emphasize alignment and risk mitigation (like Claude’s Constitutional AI), while others focus on multimodal integration (such as Gemini), open-weight access (like Mistral and Llama), or high-throughput API performance for enterprise NLP (as with Cohere’s Command R).
Available LLM Options
Choosing the right LLM for your organization depends on how well multiple models fit into your infrastructure, workflows, and compliance landscape. Below is a breakdown of today’s top models being adopted by teams.
Claude (Anthropic)
Claude 3.7 Sonnet is the latest version of Anthropic’s large language model, built for tasks like drafting content, summarizing documents, answering questions, analyzing language, and following detailed instructions. It uses a ‘Constitutional AI’ approach, meaning it’s guided by a set of hardcoded ethical guidelines during training to avoid harmful or misleading outputs.
This makes it a strong option for enterprises in regulated industries like finance, healthcare, or law, where outputs need to be accurate and cautious. Like Notion’s case. They use Claude to help users draft documents more securely. And it’s also known for maintaining structured and thoughtful responses over long conversations, which can be useful in customer-facing or compliance-sensitive applications.
Gemini (Google)
Gemini is a multimodal LLM built to handle inputs across text, code, images, audio, and video. Plus, it can interpret prompts that combine these formats—for example, generating images or an annotated chart from tabular data or reviewing UI screenshots with accompanying specs. This is where multimodal models excel. They handle tasks that mix text, images, and structured data in ways traditional LLMs can’t.
And since Gemini is deeply integrated with Google Cloud services, it makes deployment easier for teams already embedded in that infrastructure. Unlike open-weight models, however, Gemini remains part of a closed ecosystem, which may limit custom fine-tuning or offline use.
Mistral AI
Mistral puts out open-weight models like Mistral 7B and Mixtral, both of which are designed to run locally with no black-box dependencies. You’ll be able to configure, audit, and scale the model entirely within your own infrastructure while fine-tuning it without hitting API limits and inspecting the architecture top to bottom.
It’s a great option for teams dealing with strict data policies or anyone building AI products that need tight latency, full-stack visibility, or zero vendor lock-in. However, these AI models won’t hold your hand, but if you’ve got a team that knows how to optimize and scale, Mistral will give you the keys.
Llama 3 (Meta)
Llama 3.1, like its predecessors, was built with local deployment in mind. It’s an open-access model, meaning you can download it, fine-tune it, and run it entirely offline, which makes it especially useful in security-first environments. It could be government, defense, or highly siloed enterprise setups. Besides, this way, you could also optimize performance, maximize resource efficiency, and keep everything close to your data with no external APIs involved and, therefore, no data leaving your environment.
Command R (Cohere)
Command R is Cohere’s model series focused on retrieval-augmented generation (RAG) and built for high-volume natural language processing at scale. It’s also optimized for backend tasks like semantic search, long-form summarization, classification, and document-level QA.
Its API-first setup makes it easy to plug into enterprise apps without heavy ML infrastructure. Because, at the end of the day, it’s built to run fast and reliably in production. With that being said, Command R is your best bet for delivering high throughput without sacrificing accuracy. And that would be the case even if you’re managing content-heavy systems, internal knowledge bases, or structured search workflows.
Grok (xAI)
Grok is Elon Musk’s entry into the LLM race, developed by xAI and trained on live conversational data from X (formerly Twitter). It’s still evolving, but what makes it unique is the real-time data integration. Unlike most other models trained on static snapshots, Grok is wired to respond to current events and shifting public sentiment. This makes it interesting for use cases like brand monitoring, social listening, trend forecasting, or automated comms. Rather than deep technical reasoning, here you’re getting speed, recency, and a more ‘in-the-loop’ take on conversational AI.
Open AI Pro vs Other LLMs
When you get into real implementation, it’s less about how the tools scale and more about how tightly you can manage them, plus what they require in terms of access, control, and compliance.
With OpenAI, you get super high-performing models and built-in research agents with strong out-of-the-box reasoning. But it’s cloud-first and highly managed. That works for teams prioritizing ease of use, low overhead, and powerful built-in tools like Operator and Deep Research. You’re also limited to what it exposes.
In contrast, Mistral and Llama 3 let you run everything locally. You get full access to the models—architecture, weights, deployment logic—so you can customize inference, handle latency-sensitive tasks on edge systems, or meet rigid data governance requirements. But that level of control also means your team owns the ops layer and, therefore, everything from scaling to optimization.
Claude and Gemini sit somewhere in between. They’re both cloud-hosted, but each targets a specific type of use case. Claude is built for regulated industries that need structured and cautious responses. At the same time, Gemini is geared toward teams working on multimodal applications. You get access to high-quality output either way, but they also limit customization under the hood.
Then there’s Cohere’s Command R, which has been built for pure NLP throughput. If you’re scaling RAG, summarization, or enterprise search across millions of documents, this is where performance meets cost efficiency. Meanwhile, Grok brings real-time web fluency into the mix. It’s experimental, but if you need conversational AI tuned to live content streams, that’s where it’s pushing.
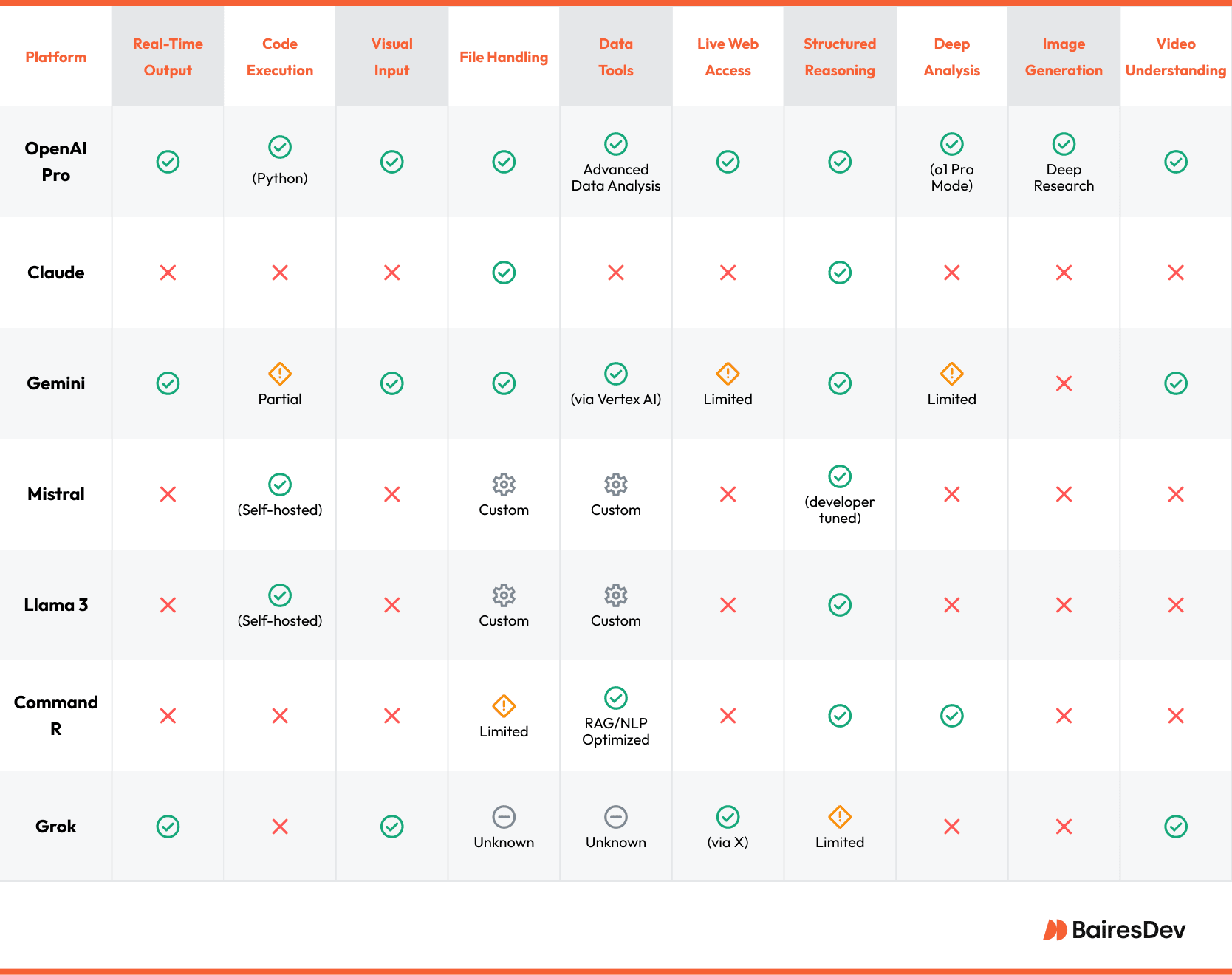
Legend:
- ✅ = Fully supported
- ❌ = Not supported
- ⚠️ = Partially supported / limited
- ⚙️ = Available with custom setup
- ❓ = Unknown or not yet documented
Implementation Strategy Starts Here
If you’re evaluating LLMs, don’t treat it like a one-off decision. Things shift fast, so focus on how systems behave in real conditions and be ready to switch when needed. Performance, cost, and reliability change over time, and no option stays perfect. You’re better off running two models (or more) side by side now and learning by doing rather than overthinking the timing.




